[Paper Review] Benchmarking Large Language Models for News Summarization
The paper conducts a comprehensive human evaluation of ten LLMs for news summarization, finding instruction tuning drives zero-shot performance more than model size, and shows high-quality freelance summaries reveal limitations of reference-based metrics.
Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries.
Motivation & Objective
- Identify design decisions that contribute to LLMs' zero-shot news summarization performance.
- Assess how model scale, prompting, and instruction tuning affect summarization quality.
- Evaluate the reliability of standard reference-based metrics for LLM summarization.
- Compare LLM outputs to high-quality human-written summaries from freelance writers.
- Provide high-quality evaluation data and resources for future benchmarking.
Proposed method
- Systematic human evaluation of ten diverse LLMs across CNN/Daily Mail and XSUM datasets.
- Use three annotator-rated criteria: faithfulness (binary), coherence (1–5), relevance (1–5).
- Compare zero-shot and few-shot prompts, and include finetuned baselines (Pegasus, BRIO).
- Recruit high-quality freelance summaries from Upwork to assess human-level performance and metric reliability.
- Analyze extractiveness vs. abstractive styles via cut-and-paste operation taxonomy.
- Release evaluation data for 18 model settings and two datasets.
Experimental results
Research questions
- RQ1Do instruction-tuned LLMs outperform scale-heavy, non-instruction-tuned models in zero-shot news summarization?
- RQ2How do high-quality human references affect the perceived vs. actual performance of LLMs and finetuned models?
- RQ3Are reference-based automatic metrics reliable for evaluating high-quality LLM outputs across CNN/Daily Mail and XSUM?
- RQ4How do LLM summaries compare to freelance human summaries in fidelity, coherence, and informativeness?
Key findings
| Model | Faithfulness CNN/DM | Coherence CNN/DM | Relevance CNN/DM | Faithfulness XSUM | Coherence XSUM | Relevance XSUM |
|---|---|---|---|---|---|---|
| GPT-3 (350M) | 0.29 | 1.92 | 1.84 | 0.26 | 2.03 | 1.90 |
| GPT-3 (6.7B) | 0.29 | 1.77 | 1.93 | 0.77 | 3.16 | 3.39 |
| GPT-3 (175B) | 0.76 | 2.65 | 3.50 | 0.80 | 2.78 | 3.52 |
| Ada Instruct v1 (350M*) | 0.88 | 4.02 | 4.26 | 0.81 | 3.90 | 3.87 |
| Curie Instruct v1 (6.7B*) | 0.97 | 4.24 | 4.59 | 0.96 | 4.27 | 4.34 |
| Davinci Instruct v2 (175B*) | 0.99 | 4.15 | 4.60 | 0.97 | 4.41 | 4.28 |
| Anthropic-LM (52B) Five-shot | 0.94 | 3.88 | 4.33 | 0.70 | 4.77 | 4.14 |
| Cohere XL (52.4B) | 0.99 | 3.42 | 4.48 | 0.63 | 4.79 | 4.00 |
| GLM (130B) | 0.94 | 3.69 | 4.24 | 0.74 | 4.72 | 4.12 |
| OPT (175B) | 0.96 | 3.64 | 4.33 | 0.67 | 4.80 | 4.01 |
| GPT-3 (350M) – (repeat) | 0.86 | 3.73 | 3.85 | - | - | - |
| GPT-3 (6.7B) – (repeat) | 0.97 | 3.87 | 4.17 | 0.75 | 4.19 | 3.36 |
| GPT-3 (175B) – (repeat) | 0.99 | 3.95 | 4.34 | 0.69 | 4.69 | 4.03 |
| Ada Instruct v1 (350M*) – (repeat) | 0.84 | 3.84 | 4.07 | 0.63 | 3.54 | 3.07 |
| Curie Instruct v1 (6.7B*) – (repeat) | 0.96 | 4.30 | 4.43 | 0.85 | 4.28 | 3.80 |
| Davinci Instruct (175B*) – (repeat) | 0.98 | 4.13 | 4.49 | 0.77 | 4.83 | 4.33 |
| Brio (Fine-tuned) | 0.94 | 3.94 | 4.40 | 0.58 | 4.68 | 3.89 |
| Pegasus (Fine-tuned) | 0.97 | 3.93 | 4.38 | 0.57 | 4.73 | 3.85 |
| Existing references | 0.84 | 3.20 | 3.94 | 0.37 | 4.13 | 3.00 |
- Instruction tuning, not model size, is the key driver of zero-shot summarization performance across datasets.
- Largest models (e.g., 175B) can be outperformed by smaller instruction-tuned models in coherence and relevance.
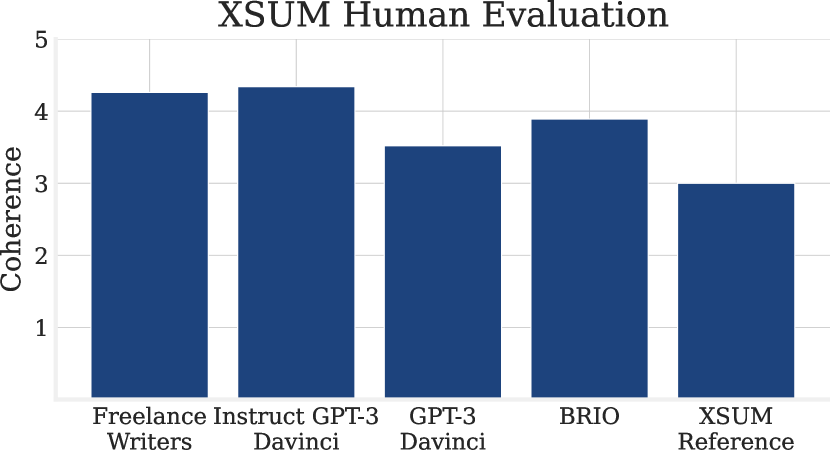
- Reference summaries in XSUM are judged worse than best LLM outputs by humans, questioning reliance on such references.
- Freelance writers produce higher-quality references than CNN/DM and XSUM baselines; Instruct Davinci is often comparable to freelance writers.
- With better quality references, Rouge-L correlation with human faithfulness improves on XSUM.
- There is substantial annotator variation in preference between LLM and freelance summaries, indicating subjective stylistic differences.

Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.