[Paper Review] Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback
The paper examines whether multiple large language models can autonomously improve negotiation strategies through self-play, AI feedback from a critic model, and in-context learning, demonstrating that some models continuously improve across rounds while others fail.
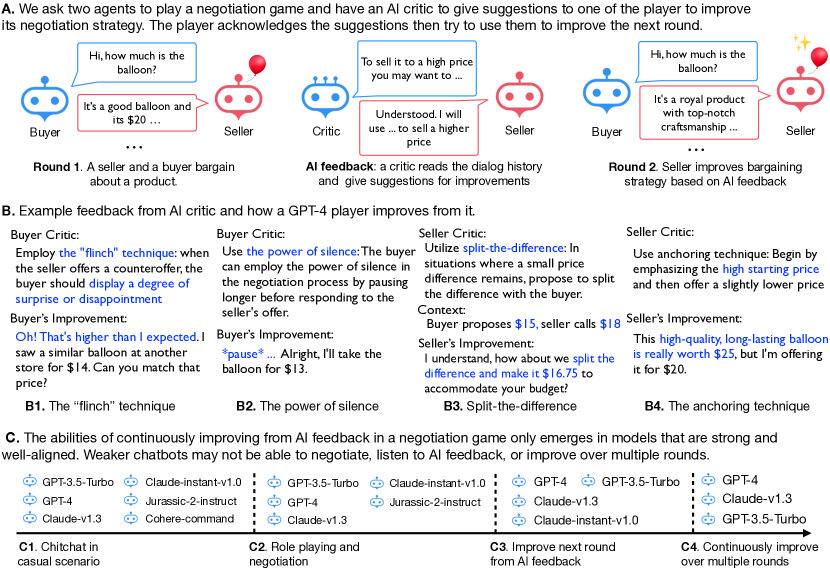
We study whether multiple large language models (LLMs) can autonomously improve each other in a negotiation game by playing, reflecting, and criticizing. We are interested in this question because if LLMs were able to improve each other, it would imply the possibility of creating strong AI agents with minimal human intervention. We ask two LLMs to negotiate with each other, playing the roles of a buyer and a seller, respectively. They aim to reach a deal with the buyer targeting a lower price and the seller a higher one. A third language model, playing the critic, provides feedback to a player to improve the player's negotiation strategies. We let the two agents play multiple rounds, using previous negotiation history and AI feedback as in-context demonstrations to improve the model's negotiation strategy iteratively. We use different LLMs (GPT and Claude) for different roles and use the deal price as the evaluation metric. Our experiments reveal multiple intriguing findings: (1) Only a subset of the language models we consider can self-play and improve the deal price from AI feedback, weaker models either do not understand the game's rules or cannot incorporate AI feedback for further improvement. (2) Models' abilities to learn from the feedback differ when playing different roles. For example, it is harder for Claude-instant to improve as the buyer than as the seller. (3) When unrolling the game to multiple rounds, stronger agents can consistently improve their performance by meaningfully using previous experiences and iterative AI feedback, yet have a higher risk of breaking the deal. We hope our work provides insightful initial explorations of having models autonomously improve each other with game playing and AI feedback.
Motivation & Objective
- Motivate the possibility of autonomous improvement of language models through game playing and AI feedback with minimal human intervention.
- Investigate a buyer-seller negotiation setup where two LLMs negotiate prices and a third LLM provides feedback to improve performance.
- Assess how different LLMs respond to AI feedback and whether they can improve over multiple rounds.
- Examine the trade-offs between higher deal prices and the likelihood of breaking a deal in iterative rounds.
Proposed method
- Two LLMs play a buyer-seller bargaining game with a defined price objective (buyer aims low, seller aims high).
- A third LLM acts as a critic, providing natural language feedback to improve the targeted player after each round.
- In-context learning is used by incorporating previous negotiation history and AI feedback as demonstrations for subsequent rounds (ICL-AIF).
- Multiple engine combinations (GPT and Claude family) are tested with gpt-3.5-turbo as baseline competitor; deal price serves as the evaluation metric.
- A moderator model classifies game states (ON-GOING, DEAL, NO DEAL) to manage rounds.
- Experiments include one-round baselines, multi-round improvements, and continuous improvement over up to five rounds.
Experimental results
Research questions
- RQ1Can multiple LLMs autonomously improve each other in a negotiation game via self-play and AI feedback?
- RQ2Which models can understand rules of bargaining and respond to AI feedback to improve over multiple rounds?
- RQ3Does the buyer role pose more difficulty for improvement than the seller role, and how does this vary by model?
- RQ4What is the trade-off between achieving higher deal prices and the likelihood of reaching a deal in iterative rounds?
Key findings
| GPT-3.5-Turbo | Claude-instant-v1.0 | Claude-v1.3 | |
|---|---|---|---|
| Before feedback | 16.26 | 14.74 | 15.40 |
| Random sampled human feedback | 16.83 (+0.57) | 16.33 (+1.59) | 16.89 (+1.58) |
| AI feedback | 17.03 (+0.77) | 15.98 (+1.24) | 16.98 (+1.58) |
- Only a subset of tested models (e.g., gpt-3.5-turbo, gpt-4, claude-v1.3) can continuously improve from iterative AI feedback across rounds.
- Buyer role generally proves harder to improve than seller role for several models; some models can still improve as buyers (e.g., GPT-4, claude-v1.3) while others cannot.
- Stronger agents can improve over multiple rounds by leveraging prior experiences and AI feedback, but higher prices increase the risk of failing to reach a deal.
- AI feedback can yield improvements comparable to human feedback and is more scalable for guiding negotiation strategies.
- In multi-round settings, increased verbosity can accompany learning, but strategic quality (not just length) drives better deal outcomes.
- The study highlights trade-offs between deal quality and deal reliability when agents learn from AI feedback.

Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.