[Paper Review] Machine Learning with a Reject Option: A survey
This survey provides a comprehensive overview of machine learning with rejection, formalizing ambiguity and novelty rejection, architectures, evaluation methods, learning approaches, and connections to related areas.
Machine learning models always make a prediction, even when it is likely to be inaccurate. This behavior should be avoided in many decision support applications, where mistakes can have severe consequences. Albeit already studied in 1970, machine learning with rejection recently gained interest. This machine learning subfield enables machine learning models to abstain from making a prediction when likely to make a mistake. This survey aims to provide an overview on machine learning with rejection. We introduce the conditions leading to two types of rejection, ambiguity and novelty rejection, which we carefully formalize. Moreover, we review and categorize strategies to evaluate a model's predictive and rejective quality. Additionally, we define the existing architectures for models with rejection and describe the standard techniques for learning such models. Finally, we provide examples of relevant application domains and show how machine learning with rejection relates to other machine learning research areas.
Motivation & Objective
- Formalize the conditions for abstention (ambiguity vs. novelty) in predictive models.
- Review and categorize architectures and learning strategies enabling rejection.
- Outline evaluation frameworks and costs for models with rejection.
- Explain how to combine multiple rejectors and relate rejection to broader ML topics.
- Highlight applications and future directions in trustworthy ML and related fields.
Proposed method
- Define the learning-with-rejection problem and extend the output space to include a reject symbol.
- Classify rejection into Ambiguity Rejection and Novelty Rejection with bias-variance and data-distribution interpretations.
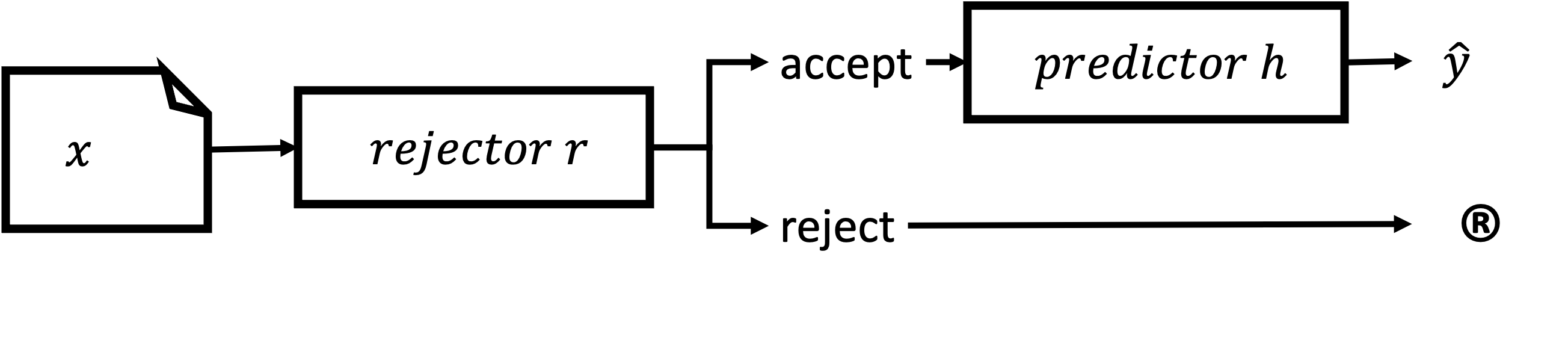
- Review architectures (Separated, Dependent, Integrated) and how rejection is implemented in prediction.
- Summarize evaluation methodologies: fixed rejection rate, trade-off curves (ARC/AURC), and cost-based metrics.
- Describe learning strategies for rejectors (density estimation, one-class classifiers, novelty scores, confidence functions).
- Discuss integration and combination of multiple rejectors and connections to uncertainty quantification, active learning, and related areas.
Experimental results
Research questions
- RQ1How to formalize when a model should abstain (ambiguity vs. novelty) from predictions?
- RQ2How to evaluate predictive and rejective quality, including trade-offs and costs?
- RQ3What architectures enable rejection, and how can we learn models with rejection?
- RQ4What are the pros and cons of separated, dependent, and integrated rejectors?
- RQ5How can multiple rejectors be combined and what is the relation to other ML research areas?
Key findings
- Provides a structured taxonomy of rejection types (Ambiguity and Novelty) and three architectural families (Separated, Dependent, Integrated).
- Outlines comprehensive evaluation frameworks including fixed rejection rate, ARC/AURC trade-offs, and cost-based metrics.
- Details learning paradigms for rejectors (density/probability estimates, one-class methods, novelty scores, confidence functions).
- Shows how rejection can improve trust, safety, and fairness in deployment while balancing prediction quality and coverage.
- Relates rejection to uncertainty quantification, anomaly detection, active learning, meta-learning, and related fields.
- Discusses practical considerations for applications and outlines future research directions.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.