[Paper Review] ReactionT5: a large-scale pre-trained model towards application of limited reaction data
ReactionT5 is a two-stage pre-trained Transformer (based on T5) that pretrains on compounds and open reaction data (ORD) to enable yield and product prediction with limited fine-tuning data; it shows competitive performance and good generalization, especially after restoring uncategorized ORD compounds.
Transformer-based deep neural networks have revolutionized the field of molecular-related prediction tasks by treating molecules as symbolic sequences. These models have been successfully applied in various organic chemical applications by pretraining them with extensive compound libraries and subsequently fine-tuning them with smaller in-house datasets for specific tasks. However, many conventional methods primarily focus on single molecules, with limited exploration of pretraining for reactions involving multiple molecules. In this paper, we propose ReactionT5, a novel model that leverages pretraining on the Open Reaction Database (ORD), a publicly available large-scale resource. We further fine-tune this model for yield prediction and product prediction tasks, demonstrating its impressive performance even with limited fine-tuning data compared to traditional models. The pre-trained ReactionT5 model is publicly accessible on the Hugging Face platform.
Motivation & Objective
- Motivate the need for scalable pre-trained models in multi-molecule reactions beyond single-molecule targets.
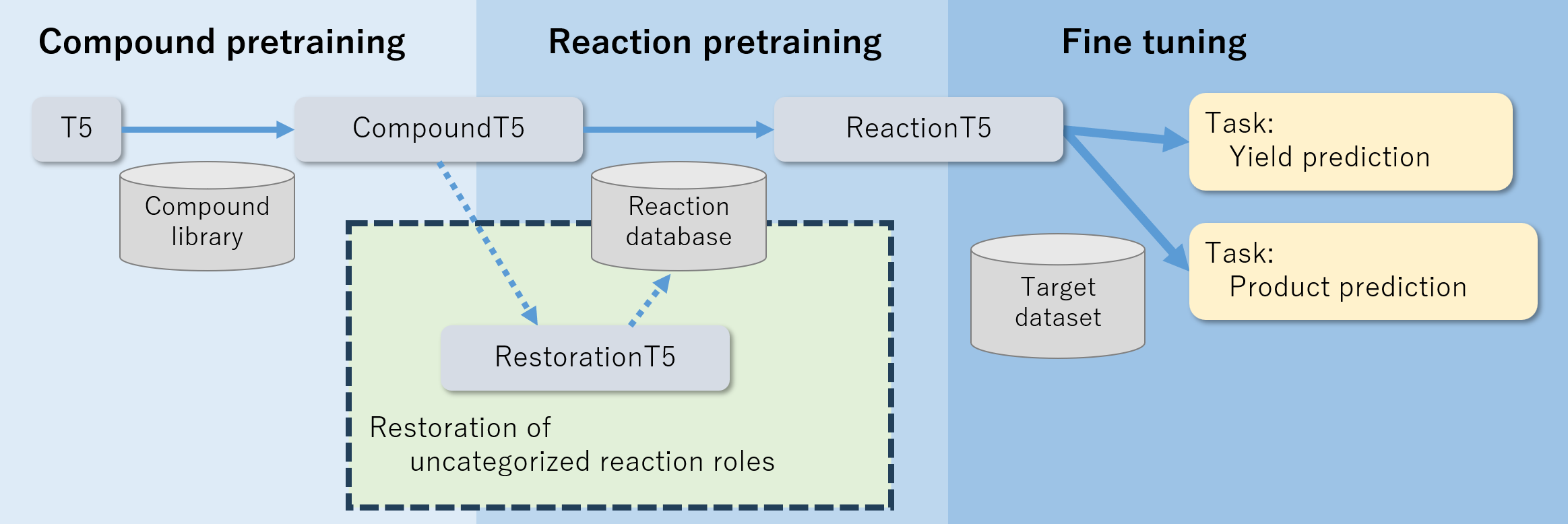
- Develop a two-stage pretraining pipeline (CompoundT5 then ReactionT5) using ZINC and ORD data.
- Demonstrate the model’s effectiveness for product and yield prediction with limited fine-tuning data.
Proposed method
- Formulate reaction tasks as text-to-text problems using T5 architecture.
- Stage 1: Compound pretraining to create CompoundT5 using SMILES from ZINC with span-masked language modeling.
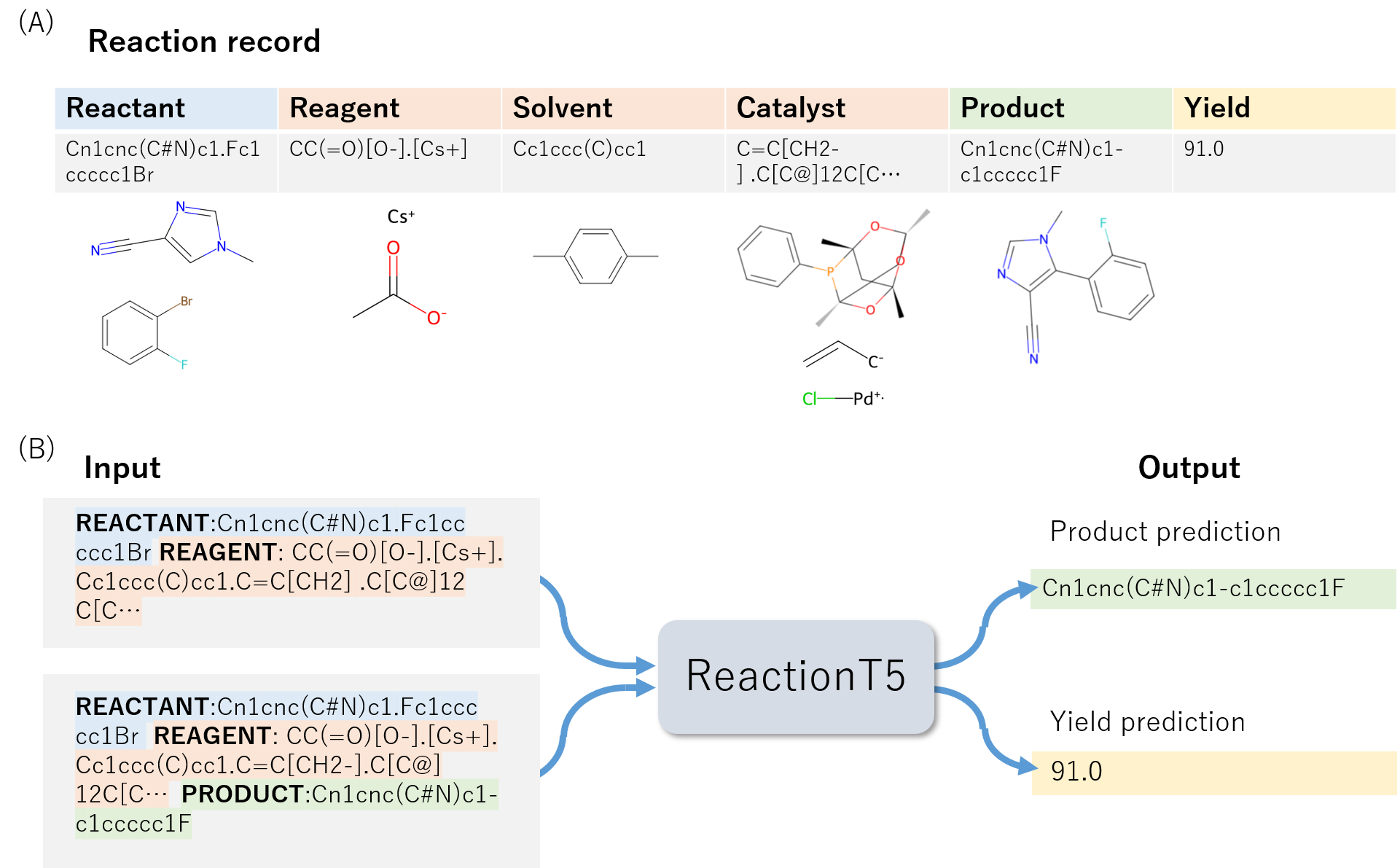
- Stage 2: Reaction pretraining to create ReactionT5 using ORD data with six reaction roles (reactant, reagent, solvent, catalyst, product, yield).
- Introduce RestorationT5 to classify uncategorized ORD compounds and restore missing roles.
- Fine-tune ReactionT5 on target datasets (USPTO for product prediction and Buchwald–Hartwig C–N cross-coupling for yield prediction).
- Use beam search with a size of 10 for product prediction and optimize length constraints to improve accuracy.
Experimental results
Research questions
- RQ1Can a two-stage pre-trained Transformer (CompoundT5 then ReactionT5) improve product and yield predictions on small target datasets?
- RQ2Does restoring uncategorized ORD compounds enhance product prediction performance with minimal fine-tuning?
- RQ3How does ReactionT5 perform in zero-shot and low-data fine-tuning scenarios compared to traditional models?
Key findings
- ReactionT5 pre-trained on ORD with restored uncategorized ORD data achieves competitive product prediction when fine-tuned with limited USPTO data.
- Fine-tuning ReactionT5 with as few as 30–200 USPTO reactions can achieve Top1 accuracy >80% on product prediction, approaching models trained on full data.
- ReactionT5 trained on ORD demonstrates strong generalization on the yield prediction task, especially on external Test 1–4 datasets.
- RestorationT5 improves ORD-based product prediction with minimal additional fine-tuning.
- Zero-shot ReactionT5 can outperform some baselines trained on 30% of data in yield prediction tasks.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.