[Paper Review] Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process
The paper formalizes Partial Dependence (PD) and Permutation Feature Importance (PFI) as estimators of ground truth DGP properties and develops variance and confidence interval methods that account for model learning variance. It introduces learner-PD and learner-PFI to capture uncertainty from model refits.
Scientists and practitioners increasingly rely on machine learning to model data and draw conclusions. Compared to statistical modeling approaches, machine learning makes fewer explicit assumptions about data structures, such as linearity. However, their model parameters usually cannot be easily related to the data generating process. To learn about the modeled relationships, partial dependence (PD) plots and permutation feature importance (PFI) are often used as interpretation methods. However, PD and PFI lack a theory that relates them to the data generating process. We formalize PD and PFI as statistical estimators of ground truth estimands rooted in the data generating process. We show that PD and PFI estimates deviate from this ground truth due to statistical biases, model variance and Monte Carlo approximation errors. To account for model variance in PD and PFI estimation, we propose the learner-PD and the learner-PFI based on model refits, and propose corrected variance and confidence interval estimators.
Motivation & Objective
- Motivate the need for connecting model interpretation tools to the data generating process (DGP).
- Formalize PD and PFI as estimators of ground truth DGP properties (DGP-PD, DGP-PFI).
- Decompose PD/PFI error into bias, variance (model and Monte Carlo), and propose variance correction approaches.
- Distinguish between model-PD/PFI and learner-PD/PFI to account for learning-process variance.
- Provide inference tools including corrected variance estimates and confidence intervals for PD/PFI.
Proposed method
- Define DGP-PD and DGP-PFI as ground truth PD/PFI applied to the true function f of the DGP.
- Represent PD and PFI as estimators incorporating bias, model variance, and Monte Carlo error; derive bias-variance decompositions.
- Introduce model-PD/model-PFI (fixed model) and learner-PD/learner-PFI (averaged over model refits) as inference targets.
- Derive variance estimators for model-PD and model-PFI and construct pointwise confidence intervals.
- Propose variance correction for learner-PD/learner-PFI to better reflect learning process uncertainty (with Nadeau-Bengio-type correction).
- Discuss how to compute learner-PD/learner-PFI using data splits and multiple refits to capture model variance.
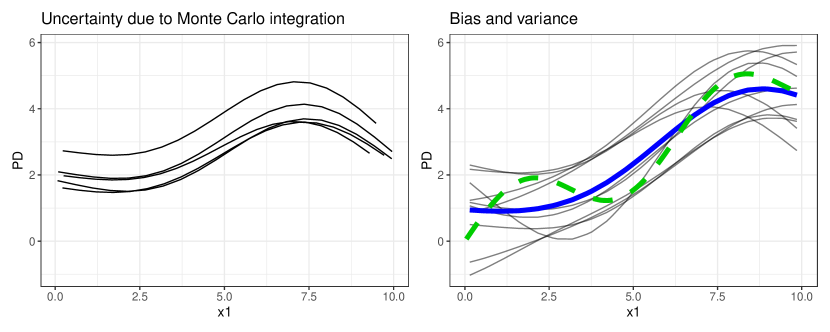
Experimental results
Research questions
- RQ1How can PD and PFI be related to the data generating process via ground truth estimands (DGP-PD, DGP-PFI)?:
- RQ2How do bias, model variance, and Monte Carlo error affect PD and PFI estimators, and how can they be quantified?
- RQ3What are appropriate variance estimators and confidence intervals for PD/PFI under fixed models (model-PD/PFI) and under model refits (learner-PD/PFI)?
- RQ4How does incorporating model variance through learner-PD/learner-PFI alter interpretation and uncertainty quantification in practice?
- RQ5What corrections improve variance estimation when resampling is used to generate multiple model fits?
Key findings
- PD and PFI can be treated as estimators of ground-truth DGP quantities (DGP-PD, DGP-PFI).
- Estimates of PD/PFI include bias and two sources of variance: model variance and Monte Carlo (MC) variance.
- Model-PD/Model-PFI quantify MC variance only and ignore learning-process variance, giving limited inference about the DGP.
- Learner-PD/Learner-PFI average over multiple model refits and capture full learning-process uncertainty, improving inference about the DGP.
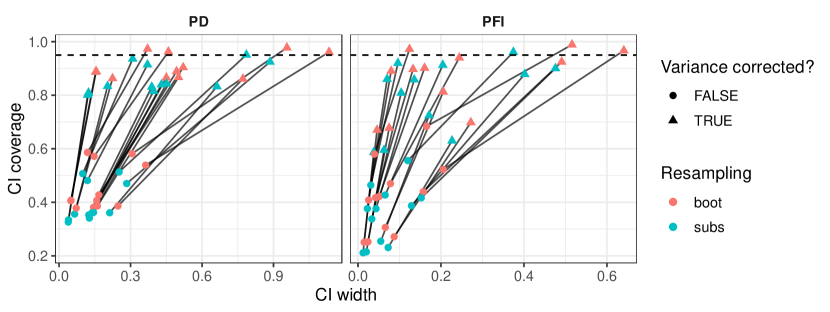
- Variance estimation for learner-PD/PFI includes a correction term to address variance underestimation when using resampling (e.g., bootstrapping).
- Confidence intervals for learner-PD/PFI are constructed using t-distributions with degrees of freedom equal to the number of model fits.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.