[논문 리뷰] Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges
본 논문은 Flan-T5 XXL을 사용하여 비구조화된 EHR 증거를 검색하고 방사선 관련 진단에 대한 요약을 제로샷 설정에서 수행하는 것을 탐구하며, LLM 출력이 표준 IR Baseline보다 선호되지만 환각에 취약하다는 것을 보여주고, 신뢰 신호가 환각을 식별하고 완화하는 데 도움이 될 수 있음을 시사한다.
Unstructured data in Electronic Health Records (EHRs) often contains critical information-complementary to imaging-that could inform radiologists' diagnoses. But the large volume of notes often associated with patients together with time constraints renders manually identifying relevant evidence practically infeasible. In this work we propose and evaluate a zero-shot strategy for using LLMs as a mechanism to efficiently retrieve and summarize unstructured evidence in patient EHR relevant to a given query. Our method entails tasking an LLM to infer whether a patient has, or is at risk of, a particular condition on the basis of associated notes; if so, we ask the model to summarize the supporting evidence. Under expert evaluation, we find that this LLM-based approach provides outputs consistently preferred to a pre-LLM information retrieval baseline. Manual evaluation is expensive, so we also propose and validate a method using an LLM to evaluate (other) LLM outputs for this task, allowing us to scale up evaluation. Our findings indicate the promise of LLMs as interfaces to EHR, but also highlight the outstanding challenge posed by "hallucinations". In this setting, however, we show that model confidence in outputs strongly correlates with faithful summaries, offering a practical means to limit confabulations.
연구 동기 및 목표
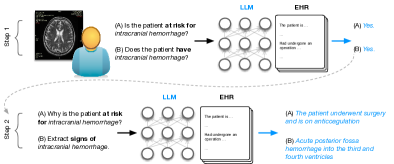
- 방사선 전문의의 진단 보조를 위해 비구조화된 EHR 노트를 LLM과 인터페이스시키는 것을 동기화한다.
- 환자에게 특정 질환의 위험 여부를 식별하고 이를 뒷받침하는 증거를 요약하기 위한 제로샷 프롬프트 전략을 평가한다.
- LLM 기반 검색을 신경 임베딩 기반과 비교하고 증거의 전문가(방사선과) 판단에 따른 유용성 및 충실성을 평가한다.
- LLM 출력에서의 환각을 특성화하고 모델의 신뢰 신호를 환각 탐지의 잠재적 도구로 탐색한다.
- EHR-인터페이스 LLM의 안전한 배치를 위한 한계 및 향후 연구 방향를 논의한다.
제안 방법
- 특정 진단에 대해 임상 노트를 제로샷 추론하는 기본 LLM으로 Flan-T5 XXL을 사용한다.
- 순차적 프롬 prompting 전략을 적용한다: 먼저 진단의 위험 여부를 결정한 다음 긍정인 경우 뒷받침 증거를 추출한다.
- 뇌파 임베딩 기반 검색 baseline(CBERT)을 GPT-3.5를 이용해 위험인자 구문을 생성하고 ClinicalBERT를 문장 임베딩에 사용하여 비교한다.
- 노트의 관련성 및 존재를Ground truth로 하는 전문가 방사선과에 의해 증거를 평가하고 0–3의 유용성 척도로 평가한다.
- 모델의 확률적 가능도(likelihood)와 자기일관성 프롬프트를 통해 환각을 탐지하고 유용성과의 상관을 분석한다.
실험 결과
연구 질문
- RQ1비구조화된 EHR 노트로부터 제로샷 LLM이 환자의 위험 여부를 판단하거나 주어진 진단을 보유하고 있는지 결정할 수 있는가?
- RQ2LLM이 생성한 증거의 질과 충실성은 신경 임베딩 검색 기반과 비교하여 어떠한가?
- RQ3LLM은 얼마나 자주 환각 증거를 만들어내며 신뢰 신호가 환각을 효과적으로 식별할 수 있는가?
- RQ4방사선과는 추출적 기반보다 추상적( abstractive) LLM 출력이 증거를 표출 및 요약하는 데 더 선호되는가?
- RQ5쿼리 용어의 차이 및 데이터셋 소스의 변화에 대해 접근법의 강건성이 어느 정도인가?
주요 결과
- LLM이 생성한 증거는 방사선과가 CBERT 기반에 비해 유용성과 간결성 면에서 더 선호하는 경향이 있다.
- HALA: 평가 샘플에서 FLAN-T5 증거의 약 9.4%가 환각으로 나타났다.
- 방사선과는 FLAN-T5 증거의 41.5%(MIMIC) 및 48.4%(BWH)를 유용하다고 판단했고, 23.0%(MIMIC) 및 18.5%(BWH)가 환각으로 판단되었다.
- 모델 신뢰 점수(가능도와 자기일관성)는 환각을 구분하는 데 강력한 성능(AUC > 0.9)을 보였고 유용성과의 상관도 있다.
- 노트에서 미래 진단을 식별하는 재현율은 부분 연구에서 0.7(140/200 정답)이다.
- 방사선과는 추상적 FLAN-T5 출력이 추출적 스니펫보다 더 정확하고 간결한 요약을 제공한다고 보고했다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.