[Paper Review] Sharing Knowledge in Multi-Task Deep Reinforcement Learning
This paper theoretically justifies and empirically demonstrates that learning a shared representation across multiple RL tasks improves sample efficiency and performance, via multi-task neural architectures and extended AVI/API bounds.
We study the benefit of sharing representations among tasks to enable the effective use of deep neural networks in Multi-Task Reinforcement Learning. We leverage the assumption that learning from different tasks, sharing common properties, is helpful to generalize the knowledge of them resulting in a more effective feature extraction compared to learning a single task. Intuitively, the resulting set of features offers performance benefits when used by Reinforcement Learning algorithms. We prove this by providing theoretical guarantees that highlight the conditions for which is convenient to share representations among tasks, extending the well-known finite-time bounds of Approximate Value-Iteration to the multi-task setting. In addition, we complement our analysis by proposing multi-task extensions of three Reinforcement Learning algorithms that we empirically evaluate on widely used Reinforcement Learning benchmarks showing significant improvements over the single-task counterparts in terms of sample efficiency and performance.
Motivation & Objective
- Motivate and formalize the benefits of sharing representations across RL tasks within multi-task reinforcement learning (MTRL).
- Provide theoretical guarantees by extending finite-time AVI/API bounds to the multi-task setting.
- Propose and validate neural-network architectures that learn a common representation for multiple tasks and assess their empirical performance on DRL benchmarks.
Proposed method
- Derive multi-task extensions of Approximate Value Iteration (AVI) and Approximate Policy Iteration (API) bounds using Gaussian complexity and Lipschitz conditions.
- Extend Maurer et al. results to multi-task settings to quantify how shared representations reduce approximation error with more tasks.
- Propose a neural network architecture with task-specific input and output blocks and a shared representation, enabling MFQI, MDQN, and MDDPG.
- Empirically evaluate multi-task variants of FQI, DQN, and DDPG on MuJoCo and classic control benchmarks.
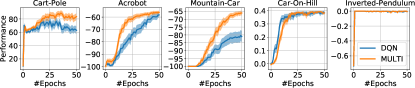
Experimental results
Research questions
- RQ1Under what conditions does sharing a representation across multiple RL tasks improve learning accuracy and convergence?
- RQ2How do multi-task bounds extend AVI/API theory to MTRL with deep networks?
- RQ3Do multi-task architectures yield better sample efficiency and performance than single-task counterparts in standard RL benchmarks?
Key findings
- Theoretical bounds show that sharing representations can reduce learning error in AVI/API in a multi-task setting.
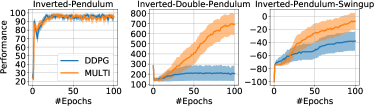
- A shared representation architecture enables MFQI, MDQN, and MDDPG to outperform single-task baselines on several benchmarks.
- Empirical results demonstrate improved sample efficiency and performance across Car-On-Hill, MuJoCo tasks, and classic control problems.
- Multi-task approaches facilitate transfer learning where pre-trained shared weights improve learning on new tasks.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.