[Paper Review] Simple and Effective Masked Diffusion Language Models
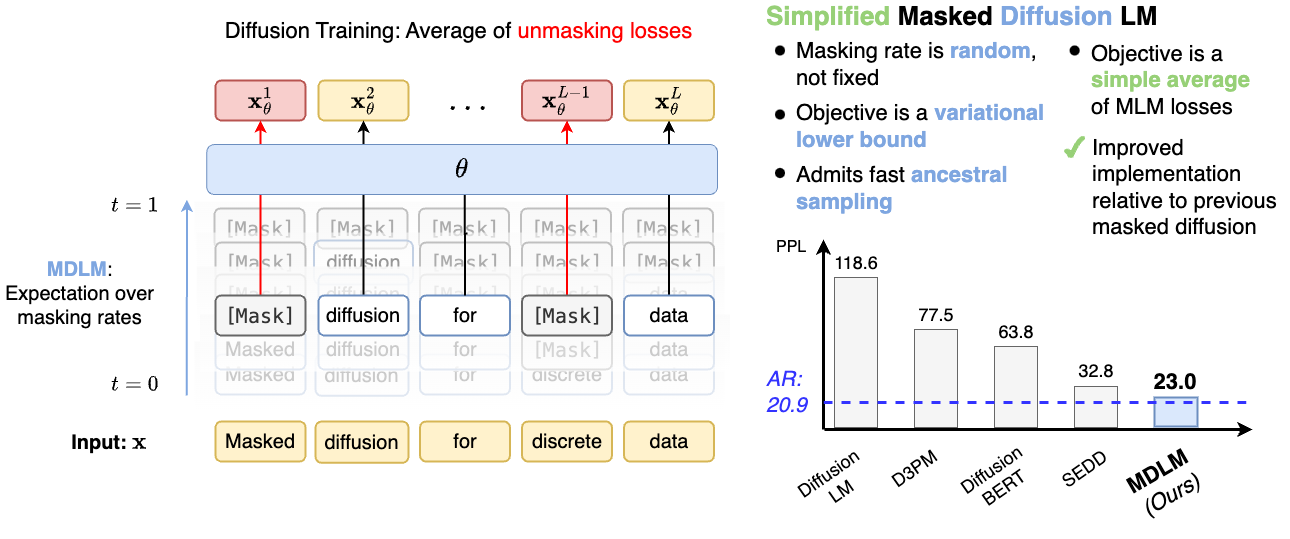
Masked diffusion language models (MDLM) with a SUBS parameterization and Rao-Blackwellized ELBO achieve new state-of-the-art among diffusion models on language benchmarks and approach autoregressive perplexity, with efficient semi-autoregressive generation.
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/mdlm
Motivation & Objective
- Motivate diffusion models for discrete language data and close the performance gap with autoregressive models.
- Develop a simple, effective MDLM framework with a principled training objective.
- Derive a Rao-Blackwellized, continuous-time variational lower bound for improved training.
- Enable efficient sampling including semi-autoregressive generation for encoder-only models.
- Extend the MDLM framework to non-language domains like DNA sequences and demonstrate generative capabilities.
Proposed method
- Define a discrete forward diffusion process on tokens that interpolates between data and a mask token.
- Introduce SUBS: a substitution-based reverse diffusion parameterization that enforces zero masking probabilities and carry-over unmasking.
- Derive a Rao-Blackwellized continuous-time NELBO that simplifies to a weighted average of MLM losses.
- Train with a time-conditional diffusion transformer architecture (DiT) and a low-discrepancy sampler for variance reduction.
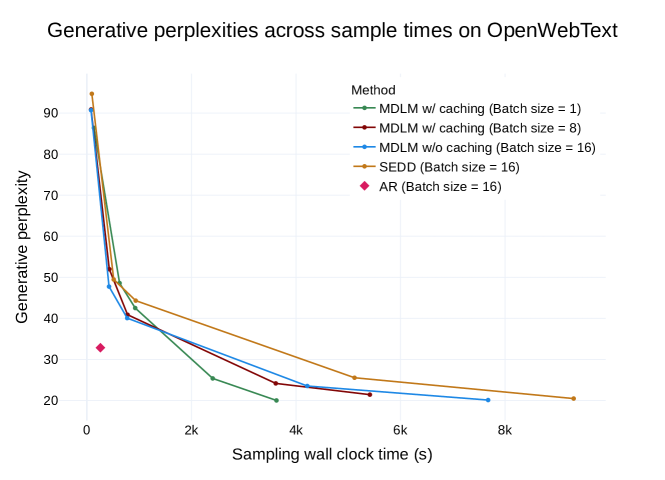
- Provide fast inference with ancestral sampling and a semi-autoregressive (SAR) generation strategy that reuses prefixes across rounds.
Experimental results
Research questions
- RQ1Can masked discrete diffusion with an effective training recipe outperform prior diffusion models on standard language modeling benchmarks?
- RQ2Does a simple SUBS parameterization yield a tighter, lower-variance variational bound for MDLM?
- RQ3Can encoder-only MDLMs with efficient samplers generate text of arbitrary length semi-autoregressively?
- RQ4How does MDLM perform on downstream tasks and cross-domain data such as DNA sequences?
- RQ5What is the impact of training choices, tokenization, and architecture on MDLM performance compared to AR models and prior diffusion methods?
Key findings
- MDLM achieves new state-of-the-art among diffusion models on LM1B and OWT benchmarks.
- MDLM approaches autoregressive perplexity, with gap reductions up to 15–25% relative to AR models depending on setting.
- The SUBS parameterization plus Rao-Blackwellized continuous-time ELBO improves likelihood and reduces variance.
- SAR decoding delivers faster generation with better generative perplexity than block-autoregressive diffusion baselines.
- MDLM demonstrates strong generative and downstream performance in DNA sequence modeling and maintains competitive downstream metrics on GLUE when fine-tuned.
- Ablation studies show critical importance of carry-over unmasking and zero-masking probabilities for performance gains.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.