[논문 리뷰] Simultaneously Localize, Segment and Rank the Camouflaged Objects
논문은 구별 가능한 영역을 로컬라이즈하고 위장된 물체를 세분화하며 위장 수준을 랭크하는 공동 모델을 도입하고, 이를 뒷받침하는 새로운 CAM-FR 데이터셋과 대규모 테스트 세트 NC4K를 제시한다.
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
연구 동기 및 목표
- 위장 conspicuousness를 모델링하는 동기를 부여하여 위장과 진화를 더 잘 이해한다.
- 랭킹 기반의 camouflaged object detection (COD) 프레임워크를 제안하여 구별 가능한 영역을 로컬라이즈하고 위장된 물체를 세분화한다.
- COD에서 로컬라이제이션, 세분화, 랭킹 작업을 지원하기 위한 새로운 데이터셋(CAM-FR 및 NC4K)을 제공한다.
- Fixation 기반 로컬라이제이션, 세분화, 그리고 위장 랭킹을 통합하는 트리플렛 태스크 학습 모델을 개발한다.
- 정량적 및 정성적 결과를 통해 COD에 대한 최첨단 성능과 해석 가능성을 입증한다.
제안 방법
- 새로운 작업으로 위장된 물체 랭킹(COR) 및 위장된 물체 로컬라이제이션(COL)을 도입하고 해당 주석을 제시한다.
- 시선 추적 기반 고정 맵과 탐지 지연으로 기존 COD 데이터셋을 재레이블링하여 로컬라이제이션과 랭킹을 위한 CAM-FR 데이터셋을 생성한다.
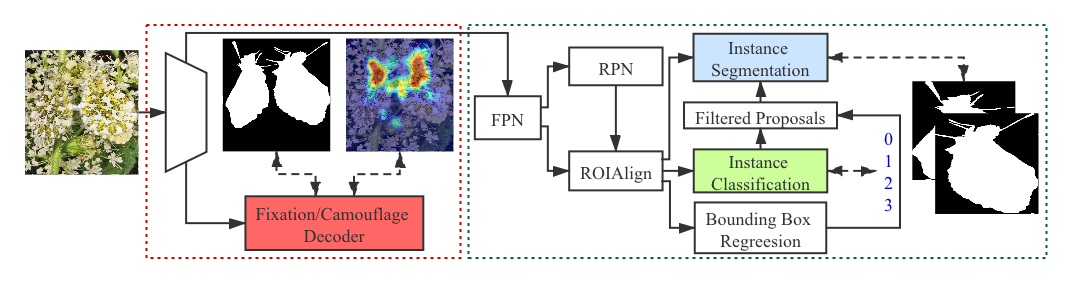
- 백본과 이중 잔여 주의(DRA) 모듈을 사용하여 구별 가능한 영역을 로컬라이즈하고 위장을 세분화하기 위해 Fixation Decoder와 Camouflage Decoder를 갖춘 공동 프레임워크를 설계한다.
- 구별 가능한 영역에서 전체 위장으로의 세분화를 안내하기 위해 역방향 주의 메커니즘을 도입한다.
- Mask R-CNN 기반 파이프라인을 확장하여 인스턴스 세분화와 랭킹(위장 수준)을 수행하고, 점진적 순위를 반영하기 위해 유사도 사전 S_p로 조정할 수 있는 랭킹 손실을 사용한다.
실험 결과
연구 질문
- RQ1위장된 물체가 그 수준의 위장을 랭크하는 동시에 효과적으로 로컬라이즈되고 세분화될 수 있는가?
- RQ2고정 기반 구별 영역 로컬라이제이션을 도입하면 COD 성능이 향상되는가?
- RQ3공동 프레임워크가 CAM-FR 작업을 태스크별 모델과 비교해 얼마나 잘 수행하는가?
- RQ4위장 인스턴스의 순위-레이블 유사성에 대한 사전의 영향은 무엇인가?
주요 결과
- 제안된 Ours 모델은 CAM-FR에서 학습될 때 구별 가능한 로컬라이제이션, 위장 탐지, 랭킹을 포함하여 COD 벤치마크에서 경쟁력 있거나 우수한 성능을 달성한다.
- 구별 가능한 영역 로컬라이제이션은 고정 기반 지표로 검증된 위장 가시성을 이끄는 신뢰할 수 있는 영역을 제공한다.
- 랭킹 구성요소(Ours_rank_new)는 랭킹 작업에서 r_mae에서 여러 베이스라인(SOLOv2, MS-RCNN 등)보다 우수하다.
- 통합된 공동 프레임워크는 구별 가능한 영역 로컬라이제이션과 CAM 기반 탐지에 이점을 보이며, 세 가지 작업을 함께 학습했을 때 성능이 향상되는 것으로 나타났다.
- 저자들은 CAM-FR과 함께 일반화 평가를 위한 새로운 대규모 테스트 데이터셋 NC4K(4,121 이미지)를 제공한다.
![Figure 3: Overview of the joint fixation and segmentation prediction network. The first part indicates the pipeline that the Fixation Decoder and Camouflage Decoder generates the corresponding maps. The second part is the structrue of the decoders, where “ASPP” is the denseaspp module [ 57 ] . The t](https://ar5iv.labs.arxiv.org/html/2103.04011/assets/figures/joint_fix_camo_overview.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.