[논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer는 시프트된 윈도우를 가진 계층형 비전 Transformer를 도입하여 선형 복잡도를 달성하고 이미지 분류, 객체 탐지, 의미론적 분할 전반에서 강력한 성능을 달성합니다.
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with extbf{S}hifted extbf{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
연구 동기 및 목표
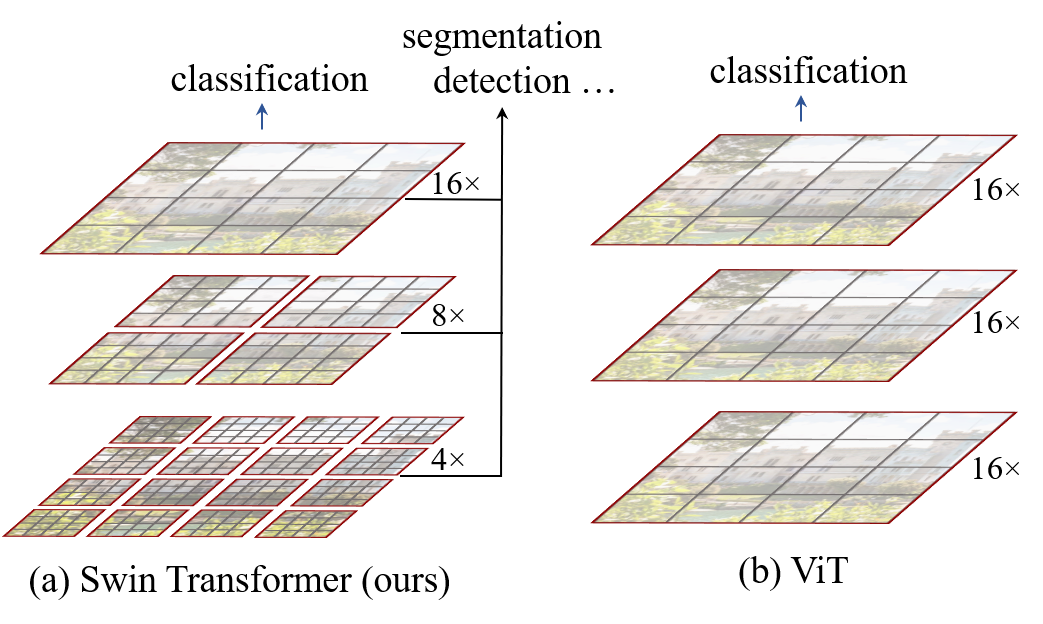
- 다중 스케일 시각적 정보를 다루는 비전을 위한 범용 Transformer 백본을 개발한다.
- 로컬 윈도우 기반 자기 주의(Self-attention)를 통해 이미지 크기에 비례하는 선형 계산 복잡도를 달성한다.
- 밀집 예측 작업을 지원하기 위해 FPN/U-Net 스타일과의 호환성을 갖춘 계층적 특징 맵을 가능하게 한다.
- shifted window partitioning으로 계층 간 윈도우를 연결하여 모델링 능력을 향상시킨다.
제안 방법
- 이미지를 패치 토큰으로 분할하고 선형으로 임베딩하여 계층적 스테이지를 형성한다.
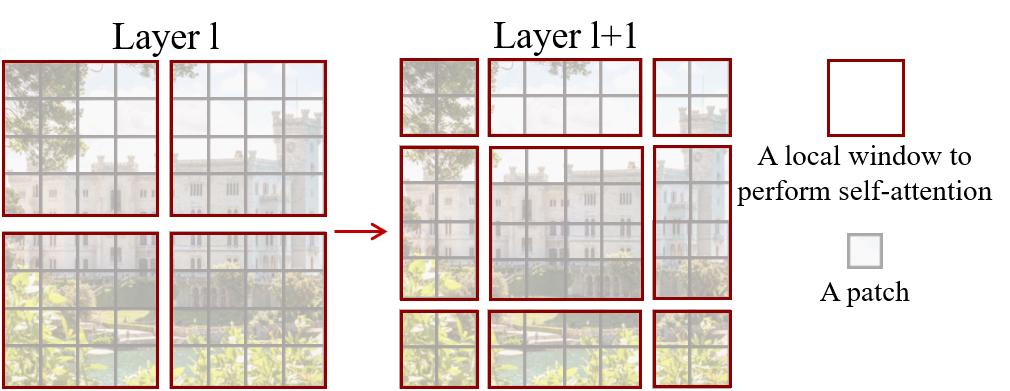
- 중첩되지 않는 윈도우 내에서 로컬로 자기 주의를 계산하여 선형 복잡도를 달성한다.
- 연속 블록 간에 shifted window 전략을 적용하여 크로스 윈도우 연결을 가능하게 한다.
- 자기 주의에서 상대 위치 바이어스를 사용하여 공간 모델링을 향상시킨다.
- GELU와 잔차 연결이 있는 MLP 뒤에 W-MSA와 SW-MSA를 갖춘 Swin Transformer 블록을 구성한다.
- 지정된 스테이지 구성과 함께 여러 모델 크기(Swin-T/Swin-S/Swin-B/Swin-L)를 제공한다.
실험 결과
연구 질문
- RQ1계층형 Transformer가 shifted window self-attention으로 분류와 밀집 시각 작업 모두에 대한 일반 백본으로 작용할 수 있는가?
- RQ2레이어 간 윈도우 분할을 시프트하는 것이 허용 가능한 지연으로 크로스 윈도우 연결을 제공하는가?
- RQ3최첨단 백본과 비교하여 Swin Transformer가 ImageNet-1K, COCO 객체 탐지/인스턴스 분할, ADE20K 의미론적 분할에서 어떤 성능을 보이는가?
주요 결과
- Swin-T는 일반 학습에서 ImageNet-1K에서 81.3%의 top-1을 달성하고, ImageNet-22K 사전 학습으로 Swin-B/L은 각각 86.4%/87.3%로 확장된다.
- COCO test-dev에서 Swin-T/B-L은 이전 최첨단을 최대 +2.7 box AP 및 +2.6 mask AP로 상회한다.
- ADE20K val에서 Swin-S/L은 각각 기존 최고 모델 대비 +5.3 mIoU 및 +3.2 mIoU를 달성한다.
- Swin Transformer는 분류, 탐지 및 분할 작업 전반에서 비슷한 대기 시간으로 DeiT 및 ResNeXt/ResNet 백본을 크게 능가한다.
- 시프트된 윈도우 설계는 상당한 모델링 이점을 제공하며 지연 오버헤드는 제한적이고 상대 위치 바이어스는 모든 작업에서 성능을 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.