[Paper Review] Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
Tag-LLM introduces domain and function input tags as learnable embeddings to adapt general LLMs to specialized domains, enabling zero-shot generalization and competitive or superior performance across NLP translation and non-linguistic tasks like protein/SMILES property prediction and drug-target binding affinity.
Large Language Models (LLMs) have demonstrated remarkable proficiency in understanding and generating natural language. However, their capabilities wane in highly specialized domains underrepresented in the pretraining corpus, such as physical and biomedical sciences. This work explores how to repurpose general LLMs into effective task solvers for specialized domains. We introduce a novel, model-agnostic framework for learning custom input tags, which are parameterized as continuous vectors appended to the LLM's embedding layer, to condition the LLM. We design two types of input tags: domain tags are used to delimit specialized representations (e.g., chemical formulas) and provide domain-relevant context; function tags are used to represent specific functions (e.g., predicting molecular properties) and compress function-solving instructions. We develop a three-stage protocol to learn these tags using auxiliary data and domain knowledge. By explicitly disentangling task domains from task functions, our method enables zero-shot generalization to unseen problems through diverse combinations of the input tags. It also boosts LLM's performance in various specialized domains, such as predicting protein or chemical properties and modeling drug-target interactions, outperforming expert models tailored to these tasks.
Motivation & Objective
- Motivate how general-purpose LLMs underperform in specialized domains and propose a reusable tagging framework to condition LLMs without full fine-tuning.
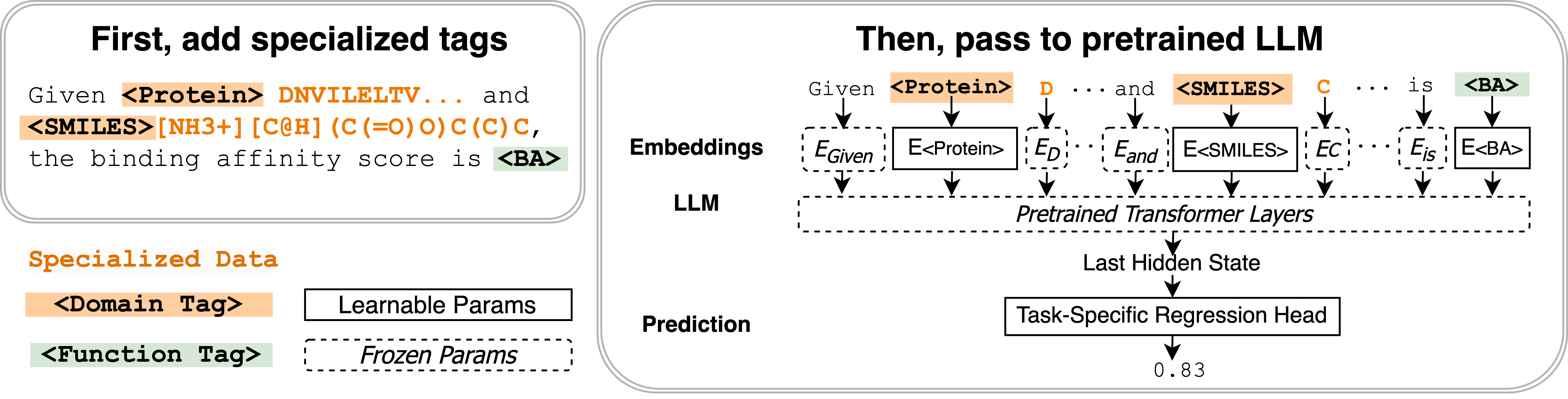
- Introduce two types of learnable input tags (domain tags and function tags) parameterized as embeddings in the LLM input.
- Develop a three-stage training protocol to learn domain and function tags using auxiliary in-domain data and domain knowledge.
- Demonstrate zero-shot generalization and competitive performance on multilingual translation and non-linguistic tasks (proteins, SMILES, drug discovery).
- Highlight the model-agnostic and plug-and-play nature of Tag-LLM and its scalability with new domains and tasks.
Proposed method
- Define two tag types: domain tags that delimit domain-specific data and encode domain-level information, and function tags that encode task semantics and can be shared across domains.
- Represent each tag as a learnable p-by-d embedding matrix appended to the LLM embedding space, initialized from the average token embedding across the vocabulary.
- Three-stage training protocol: (Stage 1) train domain tags via next-token prediction on unlabeled in-domain data; (Stage 2) train single-domain function tags with domain tags embedded in input using labeled data; (Stage 3) train cross-domain function tags with multiple domain tags to learn shared abilities.
- Extend function tags with regression heads for non-text outputs (e.g., scalar predictions) to improve numerical prediction tasks.
- Adopt a modular, hierarchical tagging framework allowing incremental tag addition and compositional problem solving.
Experimental results
Research questions
- RQ1Can a modular set of learnable input tags enable zero-shot generalization to unseen domain-task combinations?
- RQ2Do domain and function tags disentangle domain knowledge from task instructions to improve performance over standard prompt tuning?
- RQ3How does Tag-LLM perform on multilingual translation and non-linguistic scientific tasks (proteins, SMILES, drug discovery) compared to domain-specific or general baselines?
- RQ4What is the impact of tag length, enrichment, and the inclusion of regression heads on predictive accuracy?
- RQ5Can a model-agnostic tagging framework scale to new domains and tasks with minimal labeled data?
Key findings
- Domain tags act as effective context switchers for specialized data.
- A single, shared function tag can support multiple domains to address different tasks.
- Tag-LLM achieves competitive multilingual translation performance with seen domains and unseen domain-task combinations.
- Tag-LLM attains state-of-the-art results on several drug discovery datasets and often outperforms baseline PEFT methods.
- Enriching domain tags with task-relevant knowledge improves performance; regression heads help with non-text outputs and numerical predictions.
- The approach demonstrates zero-shot generalization to unseen problems through combinations of domain and function tags.

Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.