[Paper Review] The Semantic Scholar Open Data Platform
The paper describes the Semantic Scholar Open Data Platform and the Semantic Scholar Academic Graph (S2AG), outlining the data pipeline, semantic features, and public APIs/datasets.
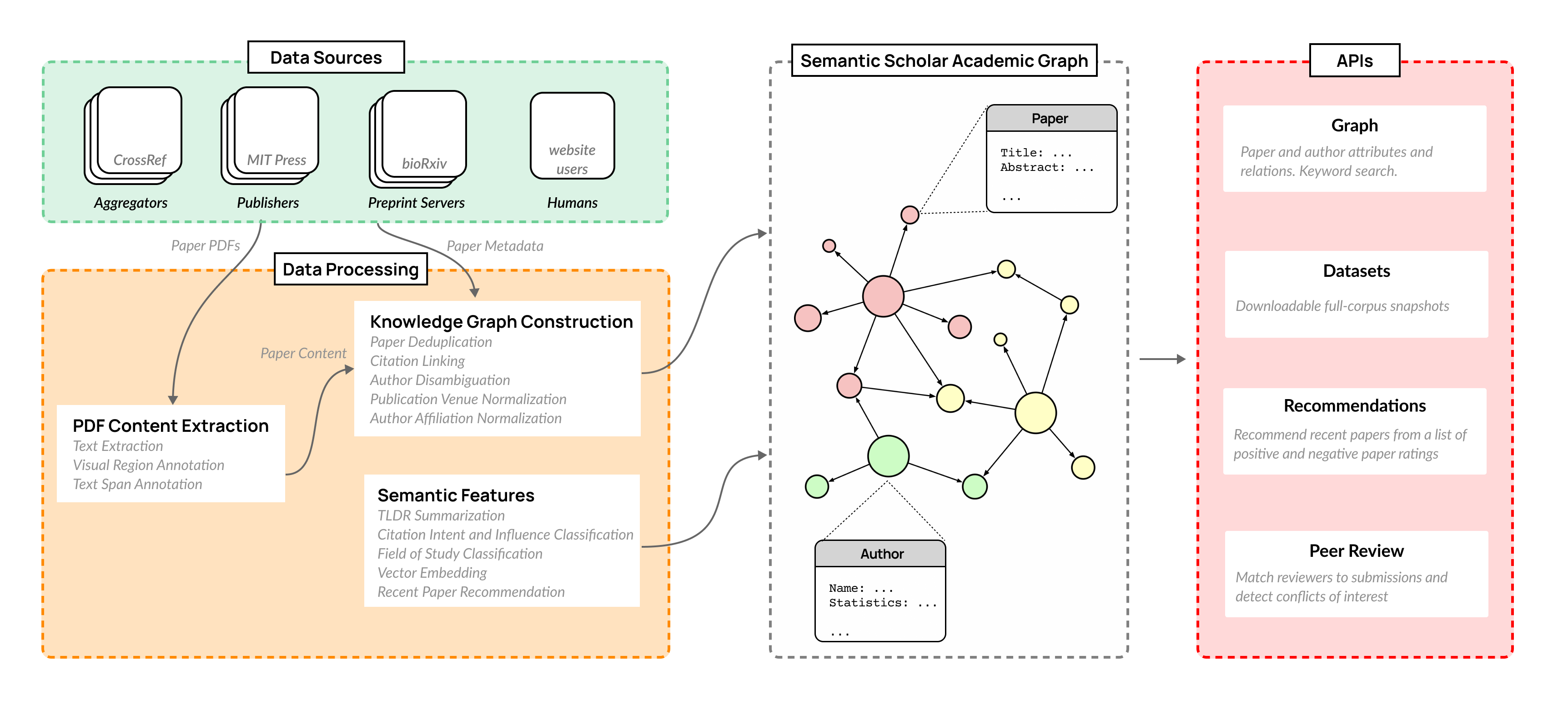
The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Motivation & Objective
- Motivate the need for automated scholarly data tools to manage information overload.
- Describe the Semantic Scholar Open Data Platform and the S2 Academic Graph (S2AG) as a large, disambiguated knowledge graph.
- Explain the data processing pipeline, data sources, and methods for extracting and structuring scholarly content.
- Detail the public APIs and downloadable datasets that provide access to S2AG and semantic features.
- Outline future directions to enhance semantic labeling, personalization, and collaboration-driven annotations.
Proposed method
- Ingests metadata and PDFs from 50+ sources to build a disambiguated knowledge graph (S2AG).
- Performs PDF content extraction to obtain structured text, sections, figures, tables, and bibliographies.
- Uses visual region annotation and text span annotation to enrich extracted content with layout and semantic labels.
- Applies deduplication (S2APLER), author disambiguation (S2AND), and affiliation normalization (S2AFF) to construct unique entities.
- Generates semantic features including TLDR summaries, citation intent/influence, fields-of-study classification, paper embeddings (SPECTER), and recommendations.
- Provides APIs and monthly dataset snapshots (papers, authors, citations, embeddings, TLDRs, venues, S2ORC) for programmatic access.
Experimental results
Research questions
- RQ1How can a large-scale, open, and disambiguated scholarly graph (S2AG) be constructed from diverse data sources?
- RQ2What semantic features (summaries, embeddings, classifications) can be added to enhance discovery and understanding of scientific literature?
- RQ3How can researchers programmatically access and download comprehensive scholarly data and semantic annotations via APIs and datasets?
- RQ4What components and pipelines are needed to keep the knowledge graph up-to-date with ongoing publications and corrections?
Key findings
- S2AG approximates a large-scale scholarly graph with 205M papers, 80M authors, 550k venues, 580M paper-author edges, 2.4B citation edges (as of the described pipeline).
- The platform delivers advanced semantic features such as structurally parsed text, TLDR summaries, vector embeddings (SPECTER), and recommendations.
- The pipeline integrates over 50 data sources, sophisticated PDF content extraction (Text Extraction, Visual Region Annotation, Text Span Annotation), and multiple normalization/disambiguation models (S2APLER, S2AND, S2AFF).
- Public APIs and monthly datasets are offered, enabling access to core metadata, abstracts, full text (where licensed), citations, embeddings, and TLDRs.
- The system provides a variety of models and datasets for semantic processing, including TLDR (CatTS), SciCite for citation intent, S2FOS for fields of study, SPECTER embeddings, and dynamic recommendations.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.