[Paper Review] The Sound of Healthcare: Improving Medical Transcription ASR Accuracy with Large Language Models
The paper investigates using large language models (LLMs) to post-process ASR transcripts for medical transcription, improving WER, MC-WER, and diarization, via zero-shot and chain-of-thought prompting on the PriMock57 dataset.
In the rapidly evolving landscape of medical documentation, transcribing clinical dialogues accurately is increasingly paramount. This study explores the potential of Large Language Models (LLMs) to enhance the accuracy of Automatic Speech Recognition (ASR) systems in medical transcription. Utilizing the PriMock57 dataset, which encompasses a diverse range of primary care consultations, we apply advanced LLMs to refine ASR-generated transcripts. Our research is multifaceted, focusing on improvements in general Word Error Rate (WER), Medical Concept WER (MC-WER) for the accurate transcription of essential medical terms, and speaker diarization accuracy. Additionally, we assess the role of LLM post-processing in improving semantic textual similarity, thereby preserving the contextual integrity of clinical dialogues. Through a series of experiments, we compare the efficacy of zero-shot and Chain-of-Thought (CoT) prompting techniques in enhancing diarization and correction accuracy. Our findings demonstrate that LLMs, particularly through CoT prompting, not only improve the diarization accuracy of existing ASR systems but also achieve state-of-the-art performance in this domain. This improvement extends to more accurately capturing medical concepts and enhancing the overall semantic coherence of the transcribed dialogues. These findings illustrate the dual role of LLMs in augmenting ASR outputs and independently excelling in transcription tasks, holding significant promise for transforming medical ASR systems and leading to more accurate and reliable patient records in healthcare settings.
Motivation & Objective
- Assess whether LLMs can enhance ASR outputs for medical transcription beyond baseline ASR performance.
- Evaluate general WER, Medical Concept WER (MC-WER), and speaker diarization accuracy after LLM post-processing.
- Compare zero-shot prompting versus chain-of-thought prompting for diarization and correction.
- Analyze the impact of punctuation quality on diarization and correction performance.
- Demonstrate whether LLMs can achieve state-of-the-art results in medical transcription tasks.
Proposed method
- Use PriMock57 dataset (57 mock consultations, ~9 hours) with ground-truth transcripts and diarization.
- Evaluate six ASR systems (GCMC, Chirp, Whisper 1, Amazon Transcribe Medical, Soniox, Deepgram Nova 2) as baselines.
- Apply multiple LLMs (Gemini Pro/Ultra, Text Bison 32k, Claude V2, GPT-4, PaLM Gecko/2, Ada embeddings, LLaMA 2) to post-process ASR outputs.
- Prompt LLMs with zero-shot templates to diarize and correct transcripts of varying segment lengths (5, 10 lines, or full transcripts).
- Implement chain-of-thought prompting to decompose into punctuation, diarization, and correction steps, with few-shot rationales.
- Apply regex parsing and Smith-Waterman alignment to handle output formatting and mitigate text degeneration; compute WER/MC-WER with standardized preprocessing.

Experimental results
Research questions
- RQ1Can LLMs improve Word Error Rate (WER) of medical ASR outputs via post-processing?
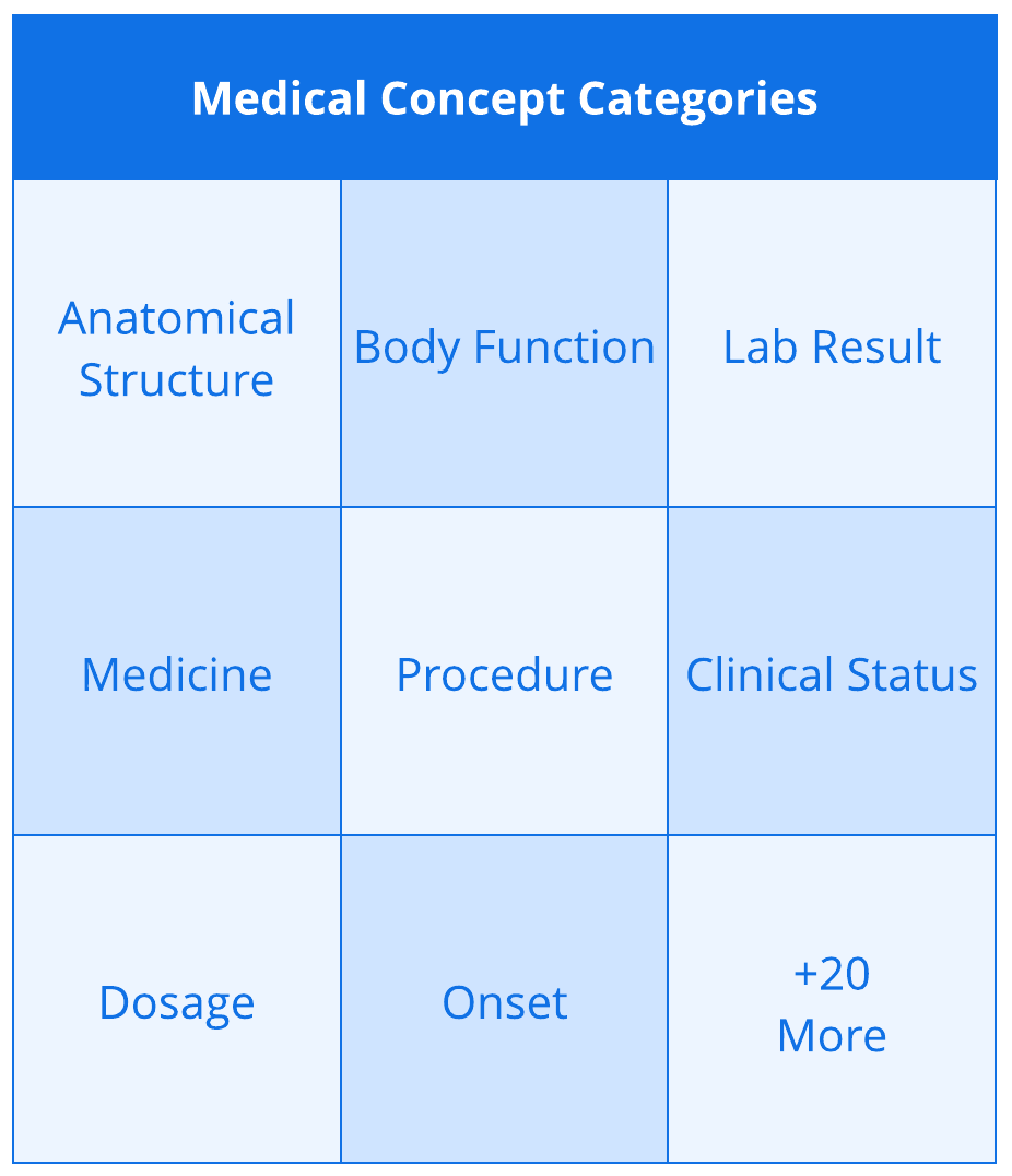
- RQ2Do LLMs improve Medical Concept WER (MC-WER) by better recognizing and normalizing medical terms?
- RQ3How does diarization accuracy fare when LLMs post-process ASR outputs, and does Chain-of-Thought prompting outperform zero-shot prompts?
- RQ4What is the impact of punctuation quality on diarization and correction performance?
- RQ5Are LLM post-processing approaches capable of achieving state-of-the-art results in doctor vs. patient diarization across different input window sizes?
Key findings
- LLM post-processing with Chain-of-Thought prompting yields superior diarization performance compared with baseline ASR across several pairings, with notable Doctor-Specific Diarizaton (D-WER) improvements.
- Certain LLM/ASR pairings (e.g., GPT-4 or Gemini Pro/Ultra with Whisper 1) achieve lower D-WER than all-ASR benchmarks in 10-line chunk experiments.
- In patient-specific diarization, LLMs are competitive and can surpass some ASR benchmarks, especially in all-at-once transcript processing where some LLM/ASR pairings outperform baselines.
- Whisper 1 generally yields the lowest MC-WER among evaluated systems, and pairing it with LLMs (e.g., GPT-4, Gemini Ultra) further reduces medical concept errors.
- Punctuation quality strongly influences diarization; adversarial punctuation from some ASR models can be mitigated by an initial punctuation enhancement step in the CoT workflow.
- The study demonstrates dual benefits: LLMs can both post-process ASR outputs and excel in transcription tasks, signaling promise for improved medical records.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.