[Paper Review] Uni3D: Exploring Unified 3D Representation at Scale
Uni3D presents a billion-parameter unified 3D foundation model that aligns 3D point clouds with image-text CLIP features, scaling from 6M to 1B and achieving state-of-the-art zero-shot, few-shot, and open-world 3D understanding.
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
Motivation & Objective
- Motivate scalable, unified 3D representation learning akin to 2D/ NLP foundation models.
- Leverage abundant 2D pretraining to initialize a 3D backbone and scale to billion-parameter models.
- Align 3D point cloud features with image-text aligned features via multi-modal contrastive learning.
- Demonstrate strong zero-shot, few-shot, and open-world performance across 3D tasks.
- Explore downstream applications like 3D painting and retrieval in the wild.
Proposed method
- Use a unified vanilla transformer (ViT-like) as the 3D backbone.
- Replace ViT patch embedding with a point tokenizer that groups points into patches and uses a tiny PointNet to produce 3D tokens.
- Pretrain end-to-end to align 3D point cloud features with image-text features from pretrained CLIP models.
- Initialize Uni3D with 2D pretrained models (e.g., EVA, DINO) or cross-modal models (CLIP), then fine-tune the 3D encoder while keeping image/text encoders fixed.
- Employ multi-modal contrastive loss across 3D, image, and text (triplet contrastive objective) and allow flexible CLIP teachers (OpenAI CLIP, EVA-CLIP, etc.).
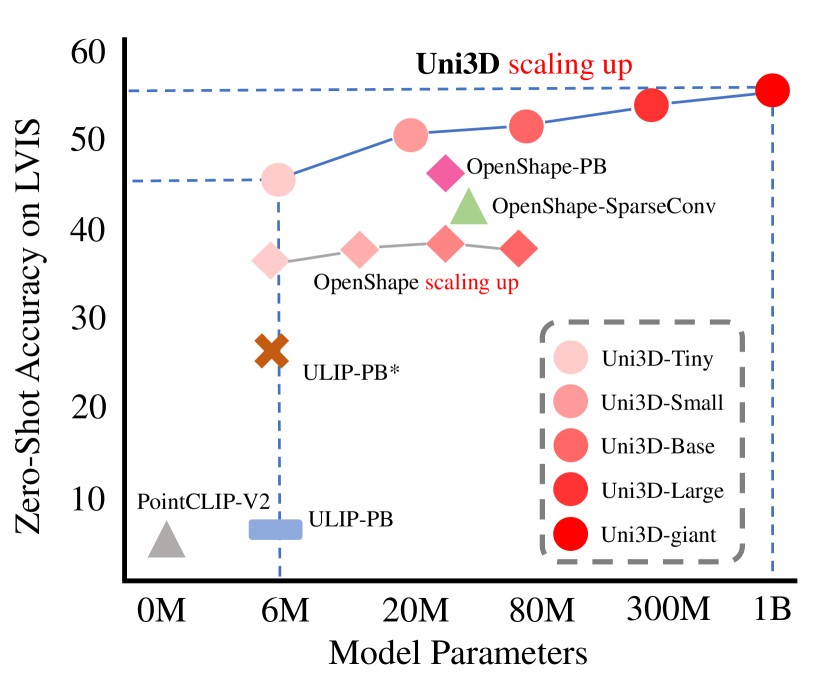
- Scale the model from 6M to 1B parameters following unified 2D/NLP scaling laws; train on nearly one million 3D shapes, 10 million images, and 70 million texts.
Experimental results
Research questions
- RQ1Can a unified 3D representation learned at billion-scale transfer effectively to diverse 3D tasks (zero-shot, few-shot, open-world, segmentation)?
- RQ2Does initializing from 2D pretraining and aligning to image-text representations enable scalable 3D learning with large-scale data?
- RQ3To what extent can CLIP-style teachers and scaling strategies improve 3D foundation models?
- RQ4What downstream capabilities (e.g., retrieval, painting, open-vocabulary segmentation) emerge from a billion-parameter 3D model?
Key findings
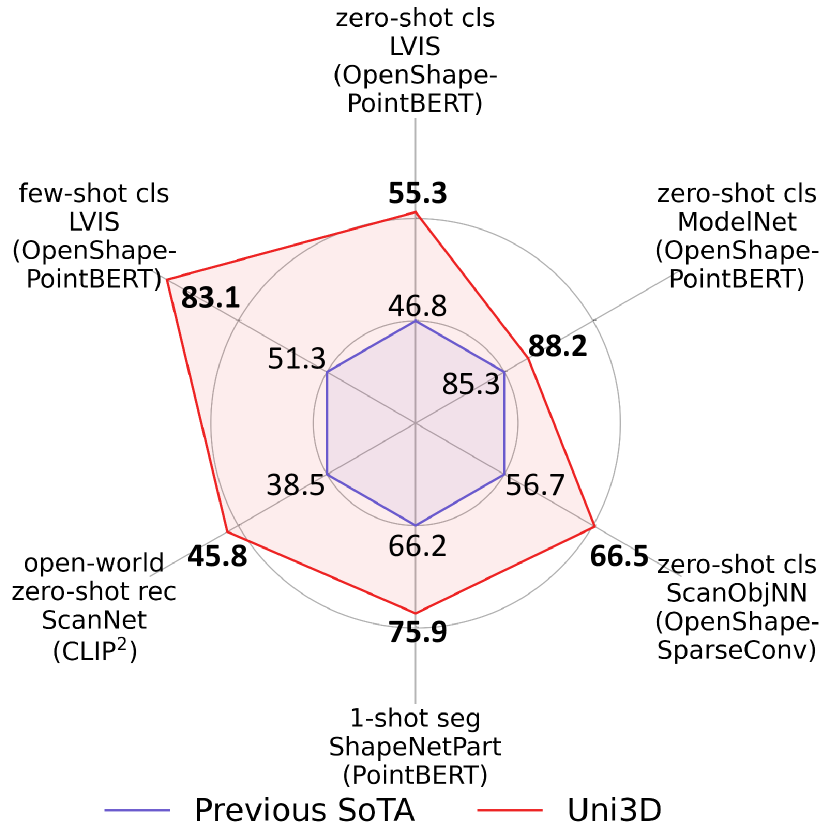
- Uni3D achieves state-of-the-art zero-shot and few-shot performance on multiple 3D benchmarks, outperforming prior methods.
- A billion-parameter Uni3D model trained with multi-modal alignment transfers well to open-world understanding and part segmentation.
- Zero-shot classification on ModelNet reaches 88.2% top-5 (as reported in the paper), illustrating strong cross-modal generalization.
- Uni3D enables practical applications such as point cloud painting and cross-modal 3D shape retrieval in the wild.
- The framework remains flexible: switching CLIP teachers and initializing from different 2D/pretrained models consistently improves results with scale.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.