[Paper Review] VerifAI: Verified Generative AI
VerifAI proposes a modular framework to verify generative AI outputs by retrieving and reasoning over multi-modal data lakes, improving reliability for tuple, table, and text outputs.
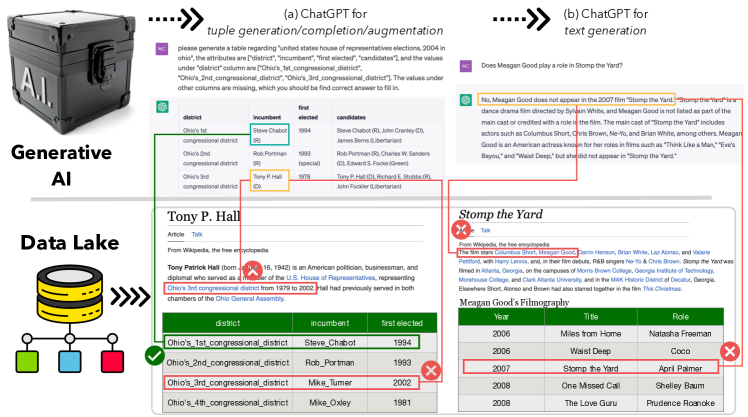
Generative AI has made significant strides, yet concerns about the accuracy and reliability of its outputs continue to grow. Such inaccuracies can have serious consequences such as inaccurate decision-making, the spread of false information, privacy violations, legal liabilities, and more. Although efforts to address these risks are underway, including explainable AI and responsible AI practices such as transparency, privacy protection, bias mitigation, and social and environmental responsibility, misinformation caused by generative AI will remain a significant challenge. We propose that verifying the outputs of generative AI from a data management perspective is an emerging issue for generative AI. This involves analyzing the underlying data from multi-modal data lakes, including text files, tables, and knowledge graphs, and assessing its quality and consistency. By doing so, we can establish a stronger foundation for evaluating the outputs of generative AI models. Such an approach can ensure the correctness of generative AI, promote transparency, and enable decision-making with greater confidence. Our vision is to promote the development of verifiable generative AI and contribute to a more trustworthy and responsible use of AI.
Motivation & Objective
- Promote a data-management perspective for verifying generative AI outputs.
- Develop a modular framework that can index, rerank, and verify generated data against data lake evidence.
- Demonstrate feasibility with preliminary experiments on tuples and text verification.
- Highlight open problems and challenges in cross-modal data discovery and verification.
Proposed method
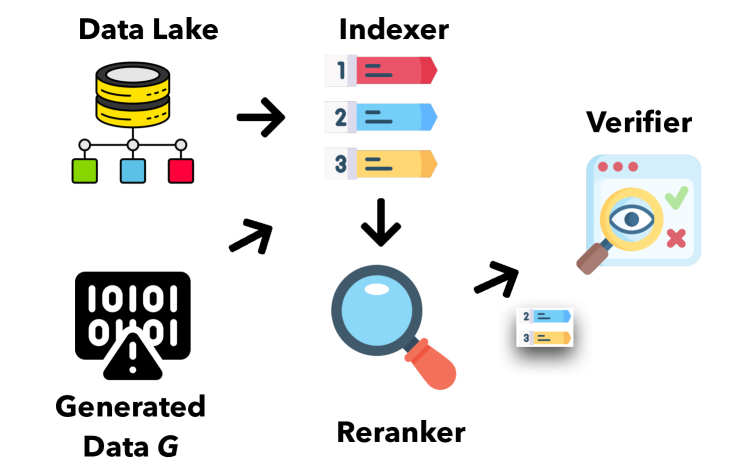
- Indexer with content-based (Elasticsearch) and vector-based (Faiss) indexing to cover multi-modal data.
- Reranker to provide fine-grained, task-specific ranking (text-text via ColBERT; text-table via OpenTFV).
- Verifier ensemble including both generic (e.g., ChatGPT) and localized models (table verification with OpenTFV/PASTA, RoBERTa-based tuple verification).
- Evidence-driven verification using a (g, x) mapping with a 0/1/2 label (verified, refuted, not related).
- Provenance handling to track verification lineage and support human debugging.
- Experimental setup validating generated tables and text verification with retrieved data from data lakes.
Experimental results
Research questions
- RQ1Can a modular verifier (Indexer-Reranker-Verifier) reliably verify or refute outputs from generative AI using data lake evidence?
- RQ2How do multi-modal data lakes support verification of generated tuples, tables, and text claims?
- RQ3What is the relative performance of generic versus localized verification models in different modalities?
- RQ4What are the practical challenges (privacy, trust, provenance) in verifying generative AI outputs?
Key findings
- VerifAI achieves high recall in retrieving relevant data for verification tasks (0.99 for tuple-to-tuple, 0.58 for text-to-text, 0.88 for textual claim-to-table).
- ChatGPT as Verifier can achieve 0.88 accuracy on (tuple, tuple) verification and outperforms some specialized models in certain text-table scenarios; PASTA can outperform ChatGPT on (text, table) verification when relevant tables are retrieved.
- Textual claim verification benefits from retrieved tables, with PASTA exceeding ChatGPT in some relevant cases, while ChatGPT generalizes better when many tables are irrelevant.
- The study highlights the importance of provenance and trustworthiness of data sources, and identifies cross-modal discovery and verification as key open problems.
- Retrieval demonstrates effectiveness for (tuple, tuple) and (textual claim, table), with weaker performance for text-file retrieval when tied to tuple-backed evidence.
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.