[Paper Review] Visual Instruction Tuning
This paper introduces LLaVA, a large multimodal model trained by instructing a vision encoder and an LLM via GPT-4 generated vision-language data, achieving strong multimodal chat and state-of-the-art on ScienceQA when combined with GPT-4.
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
Motivation & Objective
- Motivate the extension of instruction tuning to vision-language models to enable general-purpose visual assistants.
- Provide a scalable pipeline to generate multimodal instruction-following data using language models.
- Develop and evaluate LLaVA, a large multimodal model combining a vision encoder with a language model.
- Create and release benchmarks (LLaVA-Bench) for multimodal instruction-following in chat and reasoning tasks.
Proposed method
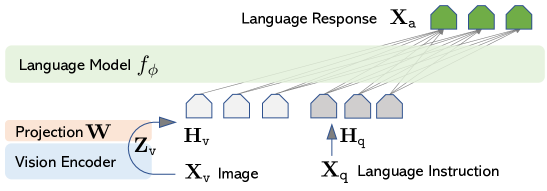
- Connect the CLIP visual encoder to the Vicuna language model via a trainable projection W to produce visual tokens.
- Generate 158K multimodal instruction-following samples using GPT-4 (and earlier ChatGPT) from image-text data, in three formats: conversation, detailed description, and complex reasoning.
- Two-stage training: Stage 1 pre-train a visual tokenizer by aligning image features with LLM embeddings using a sub-sample of CC3M; Stage 2 fine-tune end-to-end with W and φ (LM) on the generated data.
- Train with multimodal chat data and evaluate on multimodal chat and ScienceQA; ensemble with GPT-4 for improved results.
Experimental results
Research questions
- RQ1Can GPT-4 generated vision-language data enable effective visual instruction tuning of a multimodal model?
- RQ2How well can a CLIP-Vicuna architecture coupled with a GPT-4 generated data pipeline perform on open-ended multimodal tasks?
- RQ3Does combining LLaVA with GPT-4 yield state-of-the-art results on multimodal reasoning benchmarks?
- RQ4What is the value of different types of instruction-following data (conversation, detailed description, complex reasoning) for multimodal alignment?
Key findings
- LLaVA achieves strong multimodal chat capabilities, approaching multimodal GPT-4 on unseen images and instructions.
- On a synthetic multimodal instruction-following dataset, LLaVA reaches 85.1% relative score vs GPT-4.
- Fine-tuning on ScienceQA with GPT-4 ensemble yields a new state-of-the-art accuracy of 92.53%.
- LLaVA-Bench (In-the-Wild) shows substantial gains from instruction tuning, with all three data types providing the best overall performance at 85.1%.
- Ablations indicate pre-training and model scale materially impact results, with a 13B LLaVA model achieving 90.92% on ScienceQA and entering SOTA when combined with GPT-4.
![Table 3 : Example prompt from GPT-4 paper [ 36 ] to compare visual reasoning and chat capabilities. Compared to BLIP-2 [ 28 ] and OpenFlamingo [ 5 ] , LLaVA accurately follows the user’s instructions, instead of simply describing the scene. LLaVA offers a more comprehensive response than GPT-4. Even](https://ar5iv.labs.arxiv.org/html/2304.08485/assets/figures/img_extreme_ironing.png)
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.