[论文解读] Voices Obscured in Complex Environmental Settings (VOICES) corpus
VOICES 语料库提供开放、远场、多麦克风的现实噪声房间中的语音数据,使用 LibriSpeech 前景并配有多种干扰噪声,以及基线 ASR 和 SID 评估。
This paper introduces the Voices Obscured In Complex Environmental Settings (VOICES) corpus, a freely available dataset under Creative Commons BY 4.0. This dataset will promote speech and signal processing research of speech recorded by far-field microphones in noisy room conditions. Publicly available speech corpora are mostly composed of isolated speech at close-range microphony. A typical approach to better represent realistic scenarios, is to convolve clean speech with noise and simulated room response for model training. Despite these efforts, model performance degrades when tested against uncurated speech in natural conditions. For this corpus, audio was recorded in furnished rooms with background noise played in conjunction with foreground speech selected from the LibriSpeech corpus. Multiple sessions were recorded in each room to accommodate for all foreground speech-background noise combinations. Audio was recorded using twelve microphones placed throughout the room, resulting in 120 hours of audio per microphone. This work is a multi-organizational effort led by SRI International and Lab41 with the intent to push forward state-of-the-art distant microphone approaches in signal processing and speech recognition.
研究动机与目标
- 提供一个可自由访问的远场麦克风语音语料,具备现实房间声学和背景噪声,以推进语音与信号处理研究。
- 提供包含多房间、不同麦克风位置和干扰噪声的录音,以反映现实世界条件。
- 给出基线 ASR 和说话人识别结果,以在 VOICES 数据上为未来模型设定基准。
- 促进在混响环境中的事件/背景检测、源分离、语音增强和定位等研究。
提出的方法
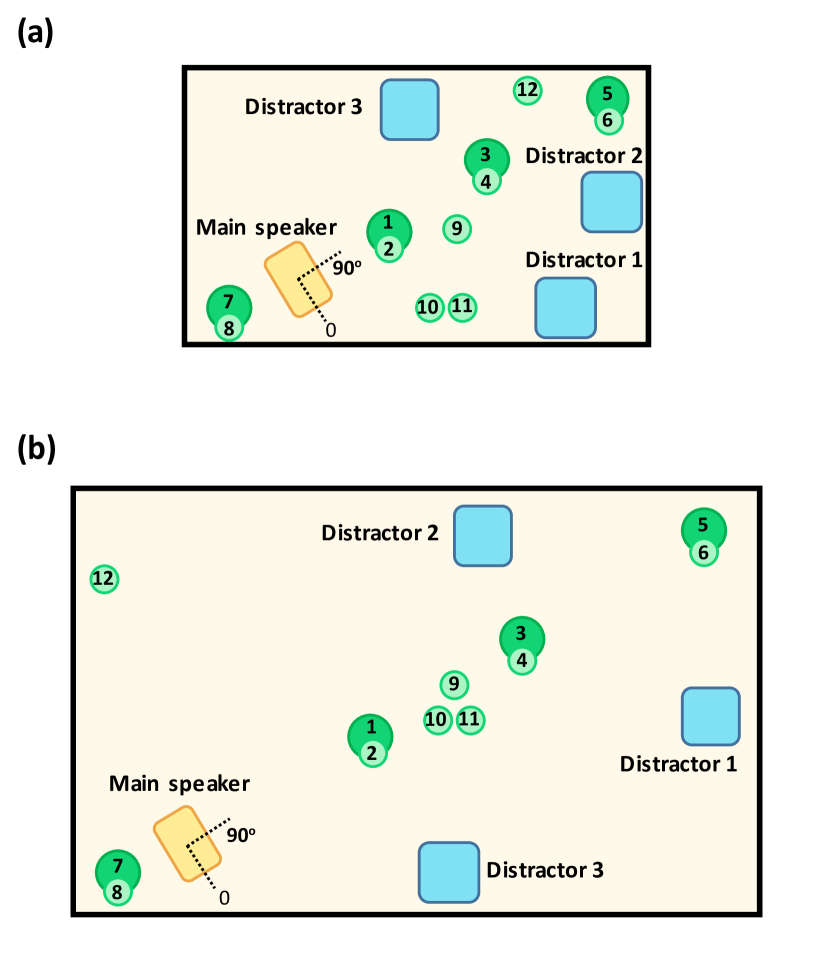
- 在两间布置好的房间中录制来自 LibriSpeech 的前景语音,房间具有不同声学特征。
- 播放同步干扰噪声(电视、音乐、 Babble)与前景语音并用 12 个远端麦克风进行录音。
- 提供每个麦克风 120 小时的数据(374,688 个音频文件),采样率 48 kHz/24-bit(并有 16 kHz 选项),包含源音频和转录文本。
- 使用轮换前景说话人模拟头部移动,并比较混响/嘈杂条件。
- 以正字转录和说话人标签进行标注;计算基本统计量(SNR、RMS、幅度)并提供基线 ASR/SID 实验。
实验结果
研究问题
- RQ1当使用近场或合成数据进行训练时,在真实房间混响和干扰噪声下,远场麦克风语音识别的表现如何?
- RQ2麦克风距离和房间声学对 VOICES 语料库中的 ASR 和 SID 性能有何影响?
- RQ3开放的 VOICES 数据能否支持在嘈杂环境中对语音/说话人识别、检测和增强的稳健声学模型开发?
- RQ4标准 ASR 与 SID 系统在 VOICES 数据上在不同噪声类型和麦克风放置下的基线性能如何?
主要发现
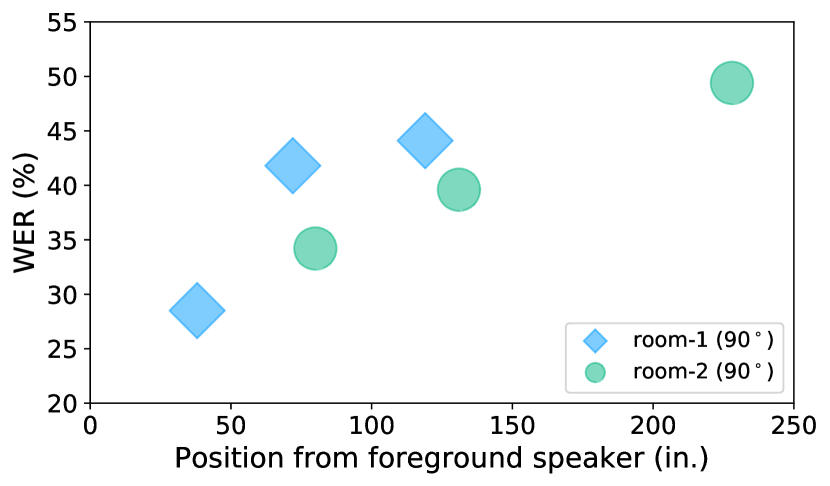
- ASR WER 随距离和干扰噪声显著增加,例如源信号 9.3%,在 babble 时为 33.0%(Room-1,90°) 的 SRI 系统。
- 距离降低 SID:在无干扰时,EER 从 5.72%(源)升至 15.1–16.6%(Room-1/Room-2 的远端麦克风)。
- 干扰噪声在不同噪声类型下(No distractor vs TV/Music/Babble)再降低 SID,约 2–3.5 个百分点的 EER。
- 各房间和条件下平均 SNR 随距离恶化;Room-1 平均 22.19 dB,Room-2 平均 19.50 dB。
- VOICES 数据集包括每个麦克风 120 小时、12 架麦克风、374,688 个音频文件,并与 LibriSpeech 前景对齐,用于说话人识别与语音识别任务。
- 基线 ASR 结果表明,在现实声学环境中相较近场条件有显著退化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。