[Paper Review] YOLOv10: Real-Time End-to-End Object Detection
YOLOv10 introduces NMS-free training with consistent dual assignments and a holistic efficiency-accuracy design, achieving state-of-the-art end-to-end real-time object detection across model scales.
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$ imes$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$ imes$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance.
Motivation & Objective
- Advance the end-to-end real-time object detection boundary for YOLOs by removing NMS post-processing.
- Develop a consistent dual-assignments training scheme for NMS-free inference.
- Holistically optimize YOLO components for efficiency and accuracy.
- Demonstrate state-of-the-art latency-accuracy trade-offs across model scales on COCO.
Proposed method
- Propose Consistent Dual Assignments for NMS-free training with dual label heads (one-to-many for rich supervision, one-to-one for inference).
- Introduce a consistent matching metric tying one-to-one and one-to-many assignments to harmonize supervision.
- Implement holistic efficiency-accuracy driven model design including lightweight classification head, spatial-channel decoupled downsampling, and rank-guided block design.
- Explore accuracy-driven design with large-kernel convolutions and a partial self-attention (PSA) module to boost performance at low cost.
- Use rank-based analysis to allocate compact blocks (CIB) where redundant, and apply large-kernel and PSA selectively by model scale.
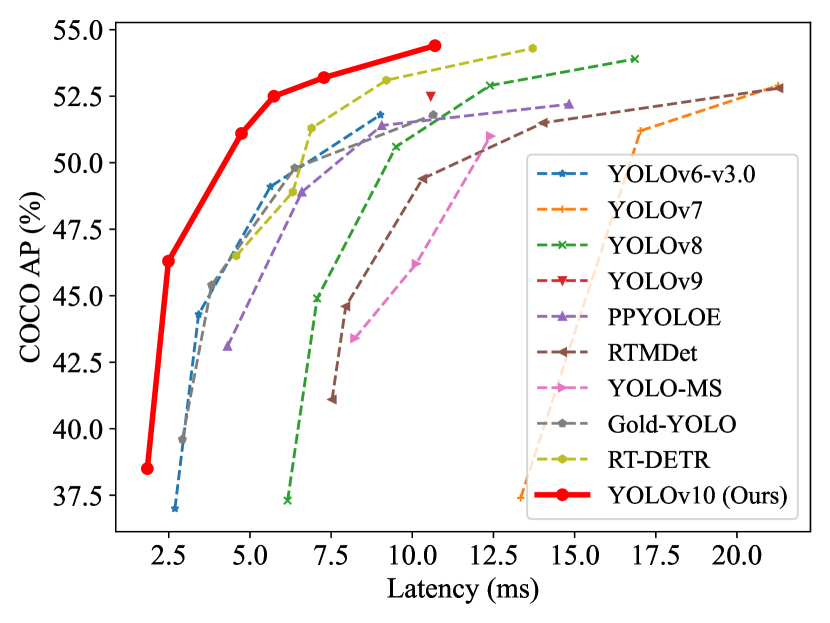
Experimental results
Research questions
- RQ1Can end-to-end NMS-free YOLOs match or surpass NMS-based YOLOs in AP while reducing inference latency?
- RQ2How can dual label assignments and a unified matching metric align supervision across heads to improve training efficiency?
- RQ3What holistic architectural changes yield better efficiency-accuracy trade-offs across model scales?
- RQ4Do large-kernel convolutions and PSA provide gains without prohibitive cost in real-time detectors?
- RQ5How can rank-guided block design and decoupled downsampling reduce redundancy without sacrificing performance?
Key findings
- YOLOv10 achieves state-of-the-art latency-accuracy trade-offs across model scales on COCO.
- YOLOv10-S is 1.8x faster than RT-DETR-R18 with similar AP, while having 2.8x fewer parameters and FLOPs.
- YOLOv10-B has 46% lower latency and 25% fewer parameters for the same performance compared to YOLOv9-C.
- YOLOv10-L and YOLOv10-X outperform YOLOv8-L/X by 0.3–1.0 AP with substantially fewer parameters (0.5–2.3x).
- YOLOv10-N/S outperform YOLOv6-3.0-N/S and RT-DETR baselines in Latency and AP for lightweight models; end-to-end latency reductions reach up to ~70% over some baselines.
![Figure 2: (a) Consistent dual assignments for NMS-free training. (b) Frequency of one-to-one assignments in Top-1/5/10 of one-to-many results for YOLOv8-S which employs $\alpha_{o2m}$ =0.5 and $\beta_{o2m}$ =6 by default [ 20 ] . For consistency, $\alpha_{o2o}$ =0.5; $\beta_{o2o}$ =6. For inconsiste](https://ar5iv.labs.arxiv.org/html/2405.14458/assets/x3.png)
Better researchstarts right now
From paper design to paper writing, dramatically reduce your research time.
No credit card · Free plan available
This review was created by AI and reviewed by human editors.