[论文解读] A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
本论文评估大型语言模型的安全性和可信赖性脆弱性,并综述如何在LLM生命周期中改编验证与确认(V&V)技术,提出一个包含虚假性/反证、验证、运行时监控以及伦理/监管考量的框架。
Large Language Models (LLMs) have exploded a new heatwave of AI for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities and limitations of the LLMs, categorising them into inherent issues, attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks as independent processes to check the alignment of their implementations against the specifications, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and regulations and ethical use. In total, 370+ references are considered to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V. While intensive research has been conducted to identify the safety and trustworthiness issues, rigorous yet practical methods are called for to ensure the alignment of LLMs with safety and trustworthiness requirements.
研究动机与目标
- 识别并分类LLMs的安全与可信赖性脆弱性(固有问题、攻击、非预期漏洞)。
- 探索如何将验证与确认技术整合到LLM生命周期中,以进行严格的安全分析。
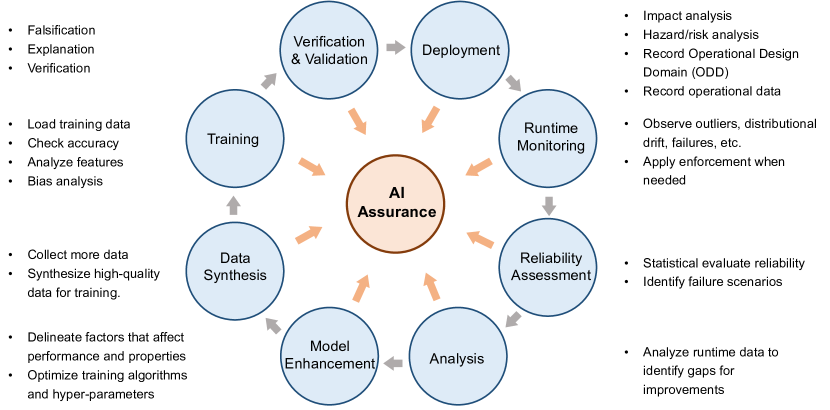
- 提出一个包括falsification/evaluation、verification、runtime monitoring,以及伦理/监管等考量的框架,以支持AI保障。
- 讨论RLHF和护栏作为LLM开发与部署中的核心安全机制。
提出的方法
- 回顾并分类已知的LLM脆弱性(固有问题、攻击、非预期漏洞)。
- 分析V&V技术(falsification、verification、runtime monitoring)在整个LLM生命周期中的适用性。
- 综合文献(370+篇参考文献)以将V&V技术映射到安全与可信赖性目标。
- 提出一个为LLMs与AI保障量身定制的互补V&V框架。
实验结果
研究问题
- RQ1LLMs在整个生命周期中主要的安全性和可信赖性脆弱性是什么?
- RQ2传统的V&V技术如何扩展或适应以在实践中验证与确认LLMs?
- RQ3RLHF和护栏在让LLMs符合安全要求方面起到什么作用?
- RQ4现有基准、监控策略与监管考虑为LLM的安全性提供了哪些指导?
- RQ5在脆弱性识别与实际验证/评估方法之间还有哪些差距?
主要发现
- LLMs表现出固有的性能和可持续性问题,影响安全性和可信赖性。
- 攻击(隐私泄露、后门、投毒、错误信息)和非预期漏洞在部署阶段带来额外风险。
- 鉴于LLM的非确定性与规模,黑箱V&V和运行时监控至关重要,需要可扩展、实用的评估方法。
- RLHF和护栏是当前安全策略的核心,但它们可能在有用性与无害性之间引入权衡。
- 在整个生命周期阶段内,为确保符合安全性和可信赖性要求,需要严格而实用的V&V方法。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。