[论文解读] A Touch, Vision, and Language Dataset for Multimodal Alignment
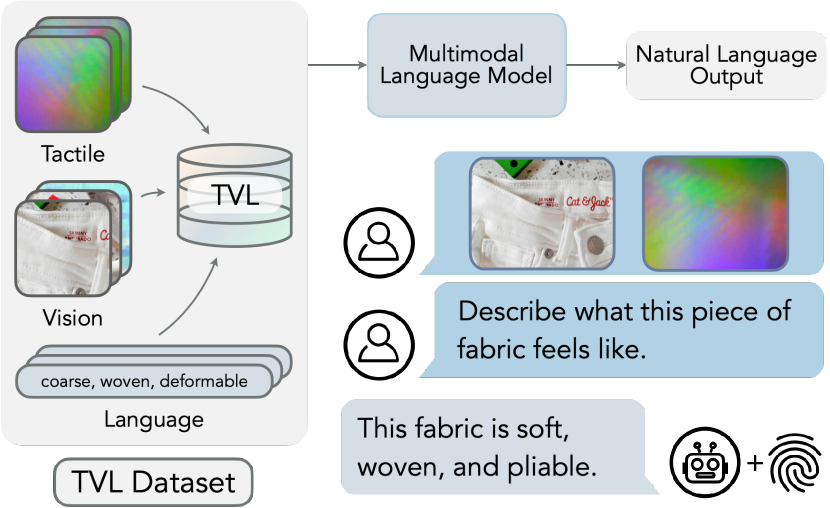
本论文介绍 TVL 数据集(44K 个视觉-触觉对,带有人工和 GPT-4V 标签)并训练一个对齐到视觉与语言的触觉编码器,从而实现一个触觉-视觉-语言模型(TVLM),该模型能够在视觉与触觉输入下生成触觉描述并提升多模态对齐。
Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
研究动机与目标
- 推动在开放词汇任务中将触觉传感整合到多模态语言模型中。
- 创建一个大规模的野外环境视觉-触觉数据集,含人工与 GPT-4V 注释。
- 训练一个与视觉-语言对齐的触觉编码器,以及一个触觉-视觉-语言模型(TVLM)。
- 展示相较于基线,触觉-视觉-语言的对齐与生成有所提升。
- 表明使用 GPT-4V 的伪标签可以补充有限的人类标签。
提出的方法
- 使用手持设备在野外数据中收集一个 44K 的视觉-触觉数据集(TVL),并获得同步的视觉与触觉读数。
- 对 10% 数据用人工触觉语言描述进行标注,其余 90% 使用 GPT-4V 进行伪标签。
- 使用在触觉-语言、触觉-视觉、视觉-语言三对并对比学习的方式训练触觉编码器,并对齐到 OpenCLIP 嵌入。
- 微调具备语言能力的模型(TVL-LLaMA),以从组合的视觉与触觉输入生成触觉描述。
- 使用 TVL 基准进行评估,包括跨模态分类任务和触觉-语义生成任务,并以真实标注进行评分。
实验结果
研究问题
- RQ1在开放词汇环境下,如何将触觉数据与视觉和语言对齐?
- RQ2混合监督机制(人为标签+ GPT-4V 标签)是否能提升触觉-视觉-语言的对齐与生成?
- RQ3对齐到视觉与文本模态的触觉编码器是否能支持开放词汇的触觉描述生成?
- RQ4在触觉-视觉-语言基准上,TVLM 与现有的视觉-语言模型和 GPT-4V 相比如何?
主要发现
- TVL 编码器在触觉-语言对齐方面实现提升,相较于仅在任一单一模态配对训练的模型,分类准确率提升 +29%。
- TVL-LLaMA 模型在 TVL 基准上优于 GPT-4V 和开源视觉-语言模型,分别至少提升 +12% 和 +32%。
- 同時使用人工标签与伪标签比仅使用单一来源的标签能实现更好的多模态理解。
- 在 TVL 基准上的开放词汇触觉分类在一个在 TVL 数据集上训练的触觉编码器上是可行的。
- GPT-4V 的伪标签在与较小比例的人类注释结合时能有效扩展数据利用率。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。