[论文解读] Advancing GenAI Assisted Programming--A Comparative Study on Prompt Efficiency and Code Quality Between GPT-4 and GLM-4
该研究比较 GPT-4 与 GLM-4 在 GenAI 辅助编程中的表现,结果显示简单提示生成代码最佳,初步确认步骤提升成功率,GPT-4 略强于 GLM-4,GenAI 可将编码效率提升 30–100 倍。
This study aims to explore the best practices for utilizing GenAI as a programming tool, through a comparative analysis between GPT-4 and GLM-4. By evaluating prompting strategies at different levels of complexity, we identify that simplest and straightforward prompting strategy yields best code generation results. Additionally, adding a CoT-like preliminary confirmation step would further increase the success rate. Our results reveal that while GPT-4 marginally outperforms GLM-4, the difference is minimal for average users. In our simplified evaluation model, we see a remarkable 30 to 100-fold increase in code generation efficiency over traditional coding norms. Our GenAI Coding Workshop highlights the effectiveness and accessibility of the prompting methodology developed in this study. We observe that GenAI-assisted coding would trigger a paradigm shift in programming landscape, which necessitates developers to take on new roles revolving around supervising and guiding GenAI, and to focus more on setting high-level objectives and engaging more towards innovation.
研究动机与目标
- Assess best practices for using GenAI as a programming tool via cross-model comparison (GPT-4 vs GLM-4).
- Determine how prompt complexity affects code generation quality and success.
- Evaluate the impact of a CoT-like preliminary confirmation on generation success.
- Provide general guidelines and insights for GenAI-assisted coding workflows.
提出的方法
- Use the game Snake as a controlled coding task to compare LLMs.
- Design four one-shot prompt levels with increasing complexity to probe code generation.
- Establish evaluation criteria: success rate, debugging efficiency, code readability, functionality richness.
- Implement a follow-up prompting loop to simulate iterative debugging and refinement.
- Collect 240 outcomes across prompts and interactions for statistical analysis.
- Analyze differences in code generation strategies (e.g., library choices) between GPT-4 and GLM-4.
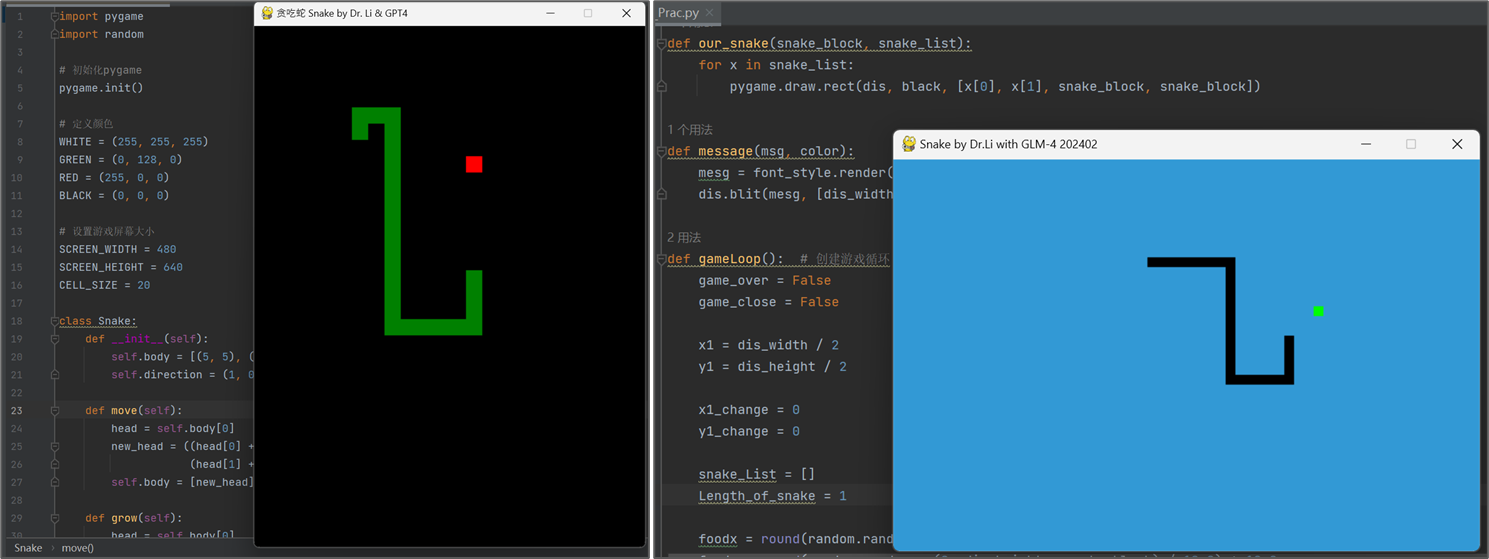
实验结果
研究问题
- RQ1How does prompt complexity affect one-shot code generation success for GPT-4 and GLM-4?
- RQ2Do CoT-like preliminary confirmations improve GenAI-assisted code generation success and efficiency?
- RQ3What are the relative strengths and weaknesses of GPT-4 vs GLM-4 in Python-based game coding tasks?
- RQ4How does code quality (readability, completeness, correctness) compare across models and prompt levels?
主要发现
- Simplest prompts (Prompt 1) achieve the highest one-shot success (GPT-4 and GLM-4).
- Preliminary confirmation rounds significantly boost one-shot success rates, aligned with Chain-of-Thought benefits.
- GPT-4 marginally outperforms GLM-4 overall, though GLM-4 can reach comparable success on the most complex prompt.
- GLM-4 frequently exhibits Type 2 failures (incomplete or truncated code) and tends to rely on specific libraries (e.g., Pygame).
- A 30–100x increase in coding efficiency is suggested for GenAI-assisted coding versus traditional norms in the simplified model.
- GenAI prompting advances enable beginners to develop functional Snake games in short timeframes, indicating portability and accessibility of the approach.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。