[论文解读] AI-assisted coding: Experiments with GPT-4
GPT-4 可以生成可用的代码并通过重构提升可读性,但人为验证仍然对测试的正确性和可靠性至关重要。GPT-4 生成的测试通常会失败,需要调试。
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.
研究动机与目标
- 评估 GPT-4 在交互式数据科学编码任务中的表现,尽量减少提示工程。
- 评估 GPT-4 重构并提升现有 Python 代码质量的能力。
- 审查 GPT-4 为其自身代码生成测试及所得到的测试覆盖率的能力。
- 评估 AI 编码助手对科学研究者的总体实用性与局限性。
提出的方法
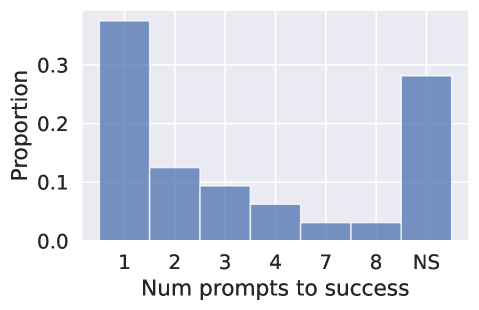
- 通过 ChatGPT 与 GPT-4 针对数据科学问题进行交互式代码生成;使用多次提示来修复和完善代码;每个问题的成功在约5分钟内判定。
- 使用 GPT-4 对现有 Python 代码进行重构,数据集来自 GitHub 的 274 个候选文件,按质量和相关性筛选;使用静态分析与可维护性指标评估代码质量。
- 自动化测试生成:GPT-4 为多个领域创建提示以生成代码和测试;执行脚本以使用 Coverage.py 和 pytest 评估可运行性和测试覆盖率。
- 在可读性、可维护性、复杂性和风格等指标上使用 flake8 和 radon 包对原始代码与重构后代码进行定量比较;统计检验(配对 t 检验并进行 FDR 校正)报告差异。
- 对局限性的评估:分析错误或幻觉输出、对人类验证的需求,以及将提示技巧(如 chain-of-thought)作为未来工作进行讨论。
实验结果
研究问题
- RQ1GPT-4 是否能在几乎不需要提示工程和人类引导的情况下为数据科学问题生成可运行的 Python 代码?
- RQ2GPT-4 是否在不改变行为的前提下对现有代码进行重构以提高可读性和可维护性?
- RQ3GPT-4 是否能为其自身代码生成具有 substantial 覆盖率的测试,这些测试的通过率有多高,或需要多少调试?
- RQ4作为面向研究人员的 AI 编码助手,GPT-4 的总体实用性与局限性是什么?
主要发现
| Metric | GitHub Median | GPT-4 Median | Cohen's d | P-value (FDR) |
|---|---|---|---|---|
| Maintainability index | 70.285 | 74.092 | 0.33 | <.001 |
| Halstead bugs | 0.081 | 0.068 | 0.13 | 0.045 |
| Halstead difficulty | 3.214 | 3.089 | 0.16 | 0.012 |
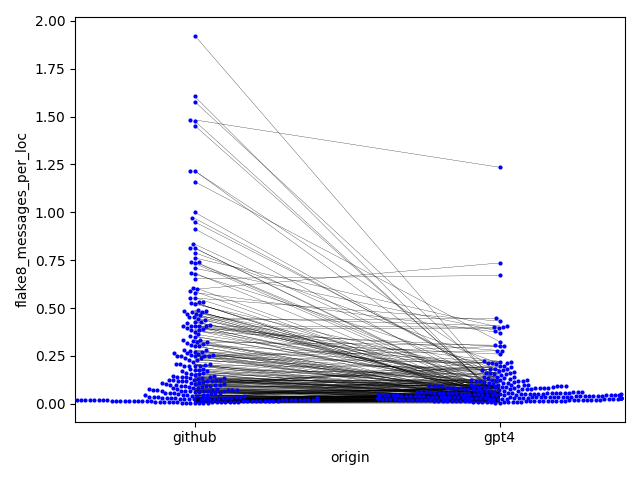
| flake8 messages per line | 0.237 | 0.089 | 0.50 | <.001 |
| Mean cyclomatic complexity | 3.462 | 3.284 | 0.18 | 0.006 |
| Number of comments | 7.81 | 7.086 | 0.08 | 0.196 |
| Logical lines of code | 46.022 | 43.372 | 0.27 | <.001 |
- 72% 的尝试 (23/32) 使用 GPT-4 得到成功的代码结果,且在第一提示下成功的比例为 37.5% (12/32)。
- 重构后的代码每行的 flake8 提示显著减少(0.23 对 0.09),表明标准一致性和可读性有所提升(Cohen's d = 0.50)。
- Code quality metrics showed improvements after refactoring: maintainability index, Halstead metrics, and cyclomatic complexity improved on average (small-to-medium effect sizes, p < .05 after FDR).
- GPT-4 为其代码生成了高覆盖率的测试,但整合后只有 100 个测试中的 45 个通过,许多测试因假设不正确或缺少上下文而失败。
- 大多数脚本(97/100)在没有失败的情况下执行完毕,但需要大量调试来解决测试与代码之间的失败或错位问题。
- 研究强调即便使用 GPT-4,人类参与在正确性方面仍然至关重要,尤其是对数学和领域特定方面。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。