[论文解读] Aligning Large Multimodal Models with Factually Augmented RLHF
本文将来自人类反馈的强化学习(RLHF)应用于大规模多模态模型(LMMs),并提出Factually Augmented RLHF(Fact-RLHF),通过将事实线索(字幕、真实选项)纳入奖励信号来减少幻觉,同时提供高质量的视觉指令微调数据以及一个新的MMHal-Bench评估基准。
Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines. We opensource our code, model, data at https://llava-rlhf.github.io.
研究动机与目标
- 激励并解决LMMs中的多模态错配与幻觉问题。
- 提出一套基于RLHF的对齐流水线,适用于视觉-语言任务。
- 引入Factually Augmented RLHF,用事实信息校准奖励。
- 通过高质量的人工注释多模态数据提升视觉指令微调数据。
- 开发MMHal-Bench,专门对幻觉进行惩罚并评估实际世界的对齐。
提出的方法
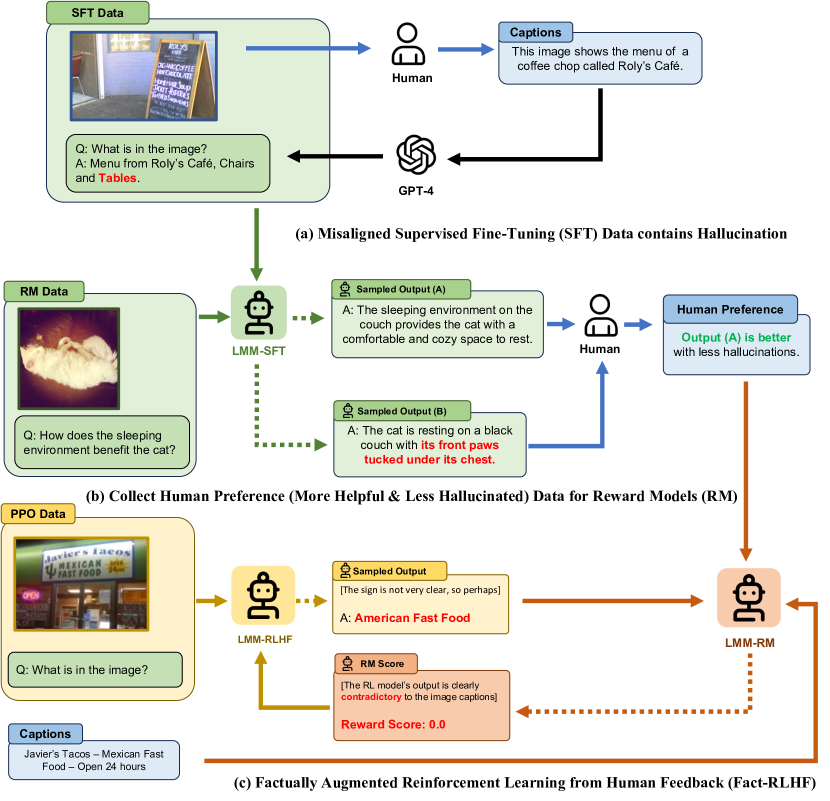
- 对LMMs应用RLHF,采用三阶段流水线:多模态有监督微调、多模态偏好建模,以及带奖励模型的强化学习。
- 引入Fact-RLHF,其中奖励模型在训练和推理阶段使用额外的事实信息(图像字幕、A-OKVQA推理、真实选项)以抑制奖励劫持。
- 结合符号化奖励(真实选项)和长度惩罚,以阻止冗长、易产生幻觉的输出。
- 通过将VQA-v2、A-OKVQA和Flickr30k转换为更结构化的高质量视觉指令微调数据集来扩充训练数据。
- 使用基于LoRA的微调对模型进行扩展以实现高效的RLHF;使用带KL惩罚的PPO来稳定更新。
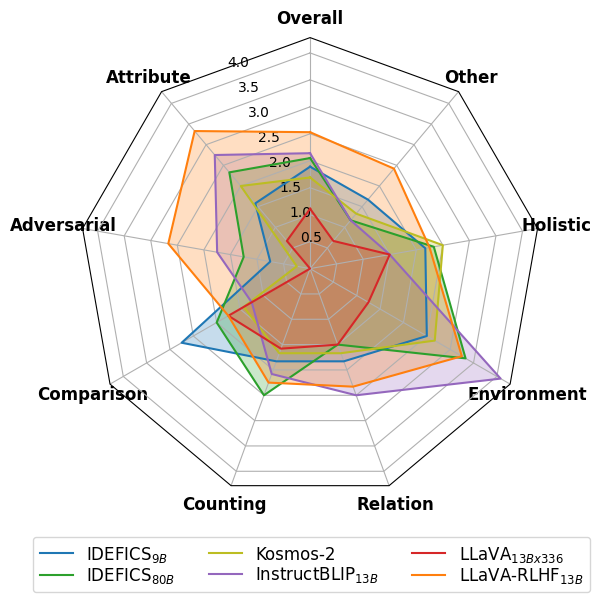
实验结果
研究问题
- RQ1如何有效地将RLHF改编为使大规模多模态模型与视觉真实信息对齐?
- RQ2将事实信息纳入奖励模型是否能减少多模态幻觉和奖励劫持?
- RQ3高质量的视觉指令微调数据对LMM的能力与对齐有何影响?
- RQ4如何使用专门的MMHal-Bench来测量和基准测试LMM输出中的幻觉?
- RQ5在能力与对齐基准上,Fact-RLHF相对于标准RLHF的相对提升是多少?
主要发现
- Fact-RLHF在以人为偏好为基准的对齐方面优于标准RLHF,并减少幻觉。
- 高质量的视觉指令微调数据显著提升如MMBench和POPE等能力基准,尤其是对较大模型。
- RLHF提升了人类对齐基准(MMHal-Bench、LLaVA-Bench),但在较小规模时对能力基准可能效果参差。
- MMHal-Bench揭示LMM在非地面化问题上容易幻觉,Fact-RLHF降低了此类错误。
- LLaVA- RLHF在LLaVA-Bench上达到94%,在MMHal-Bench比基线提升60%,在MMBench和POPE上结果具有竞争力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。