[论文解读] AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
AssistGPT 是一个通用多模态AI系统,交错语言与代码推理(计划、执行、检查、学习),协调多种工具完成复杂视觉任务,在 A-OKVQA 和 NExT-QA 基准上实现最先进的结果。
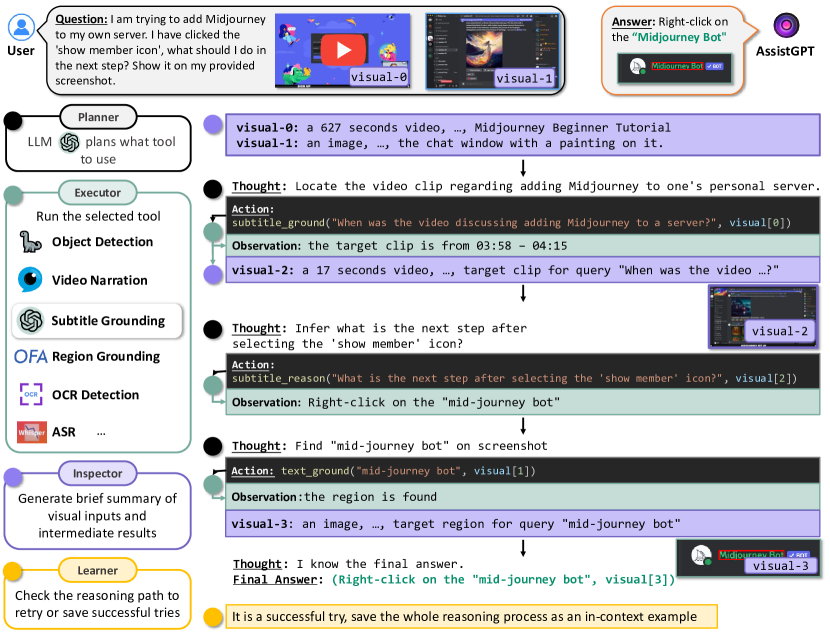
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
研究动机与目标
- 阐明需要一个通用的多模态助手,能够处理多样的视觉输入和灵活的任务,超越单图像推理。
- 提出一个包含四个模块的 PEIL 框架,将语言与代码交错以规划工具使用并管理中间结果。
- 通过在 A-OKVQA 和 NExT-QA 上的最先进结果展示系统的有效性,并说明其对复杂真实世界场景的处理能力。
- 展示 Learner 组件如何通过上下文学习和成功轨迹的复用实现自我提升。
提出的方法
- 规划器使用一个大型语言模型(GPT-4)生成两部分输出:引导下一步的自然语言思路(Thought),以及调用外部工具的结构化行动(Action)。
- 执行器对工具特定代码进行校验并执行,后处理结果以生成观测(Observations)并反馈给规划器。
- 检查器通过记录元数据和摘要来管理视觉输入与中间结果,帮助规划器选择信息源与工具。
- 学习者评估推理、执行自检,并将成功的轨迹作为上下文示例存储以提升未来预测。
实验结果
研究问题
- RQ1AssistGPT 是否能通过语言与代码交错规划在复杂多模态任务上取得强劲表现?
- RQ2每个 PEIL 组件(规划器、执行器、检查器、学习者)对任务性能与鲁棒性的影响是什么?
- RQ3AssistGPT 与现有多模态系统在 A-OKVQA 与 NExT-QA 等基准上的表现对比如何?
- RQ4学习者能否实现有意义的上下文学习和随时间的自我提升?
- RQ5灵活输入(图像、视频、逐字稿、字幕)是否能被检查器和工具集有效处理?
主要发现
| 模型 | D.A. | M.C. |
|---|---|---|
| AssistGPT (BLIP2 FlanT5 XL) | 42.6 | 73.7 |
| AssistGPT (Ins.BLIP Vicuna-7B) | 44.3 | 74.7 |
| InstructBLIP Vicuna-7B | 64.0 | 75.7 |
| PromptCap | 56.3 | 73.2 |
| GPV-2 | 48.6 | 60.3 |
| LXMERT | 30.7 | 51.4 |
| KRISP | 33.7 | 51.9 |
- AssistGPT 变体在 A-OKVQA 的多项选择题轨道取得与最先进水平相当的结果,在直接回答任务上也具有可比性。
- 消融研究表明,带 Learner 组件的语言与代码交错推理(PEIL)能获得最强性能,超过仅推理和纯 ReAct 的基线。
- 在 NExT-QA 上,AssistGPT 在因果、时序和描述性问答上取得具竞争力的分数,优于若干近期基线。
- 学习者的自检和 GT-check 变体显著提升鲁棒性和上下文学习能力,成功的轨迹已存储以供未来查询。
- 与前期的基于 LLM 的模块化系统相比,AssistGPT 展现了对复杂、多源视觉输入和长格式视频推理的改进处理。
- 定性结果 illustrate 通过计划修订和工具再调用,对复杂问题的有效分解与自我纠错行为。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。