[论文解读] Attacking Large Language Models with Projected Gradient Descent
论文提出了一种针对大型语言模型的投影梯度下降(PGD)攻击,该攻击在连续松弛的令牌序列上进行,与离散优化方法的攻击强度相当,且运行时间快高达10倍。
Current LLM alignment methods are readily broken through specifically crafted adversarial prompts. While crafting adversarial prompts using discrete optimization is highly effective, such attacks typically use more than 100,000 LLM calls. This high computational cost makes them unsuitable for, e.g., quantitative analyses and adversarial training. To remedy this, we revisit Projected Gradient Descent (PGD) on the continuously relaxed input prompt. Although previous attempts with ordinary gradient-based attacks largely failed, we show that carefully controlling the error introduced by the continuous relaxation tremendously boosts their efficacy. Our PGD for LLMs is up to one order of magnitude faster than state-of-the-art discrete optimization to achieve the same devastating attack results.
研究动机与目标
- 推动并实现LLM的高效自动化红队测试。
- 证明基于梯度的优化结合连续松弛在有效性上可媲美离散攻击。
- 构建一个基于投影的框架,使优化保持在概率单纯形上并控制松弛误差。
- 展示在大规模评估和对抗训练中相对于最先进攻击的效率提升。
提出的方法
- 将输入的单热向量在概率单纯形上进行连续松弛形式化。
- 对松弛后的输入应用基于梯度的更新,并在每步后重新投影回到单纯形上。
- 使用熵(基尼)投影来约束松弛误差并鼓励离散化。
- 通过令牌掩码引入可微分的长度灵活性,使在注意力中的令牌插入/删除平滑进行。
- 通过对每个令牌在松弛后取argmax进行离散化,并在得到的序列上评估攻击目标。
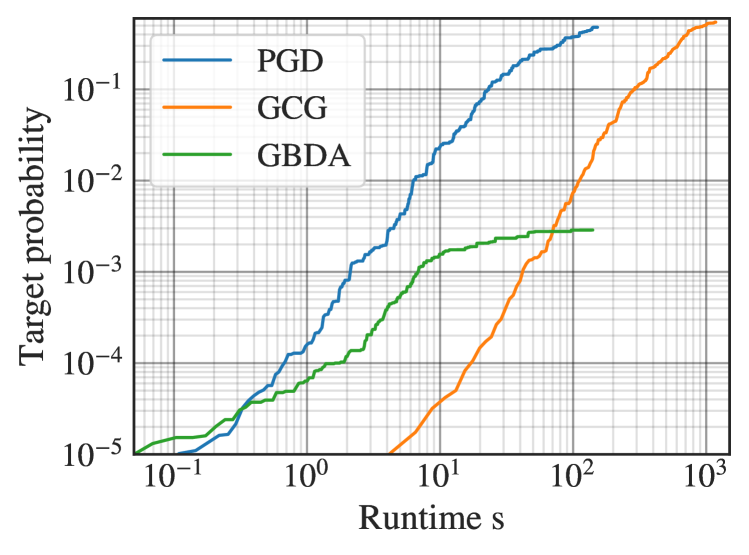
实验结果
研究问题
- RQ1基于梯度的优化结合连续松弛是否能够在越狱任务中有效攻击对齐的LLM?
- RQ2就攻击有效性和计算效率而言,PGD与离散优化方法相比如何?
- RQ3基于熵的投影是否通过抵消松弛误差来提高可靠性?
- RQ4允许可变序列长度是否会进一步提升攻击性能?
主要发现
| Attack | ASR @ 60 s | Iter. / s |
|---|---|---|
| PGD | 87 % | 28.2 |
| GCG | 83 % | 0.3 |
| GBDA | 40 % | 29.3 |
- PGD达到与最先进的离散优化方法相同或更好的攻击强度,运行时间低至一个数量级。
- 在行为越狱任务中,PGD在60秒时达到87%的攻击成功率,GCG为83%,GBDA为40%。
- PGD将搜索空间从大约65,000个减少到每个位置大约10个候选令牌。
- 消融的交叉熵结果显示改进:0.092±0.014(无松弛),0.085±0.010(无熵投影的松弛),0.078±0.009(有熵投影的松弛)。
- PGD的效率优势在 Vicuna 7B、Falcon 7B 和 Falcon 7B Instruct 模型上得到证实。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。