[论文解读] Automated Unit Test Improvement using Large Language Models at Meta
Meta 的 TestGen-LLM 使用大模型自动改进现有的人类编写的 Kotlin 测试类,提供可验证的改进和不回归保障,部署在 Instagram 和 Facebook 的测试马拉松中。
This paper describes Meta's TestGen-LLM tool, which uses LLMs to automatically improve existing human-written tests. TestGen-LLM verifies that its generated test classes successfully clear a set of filters that assure measurable improvement over the original test suite, thereby eliminating problems due to LLM hallucination. We describe the deployment of TestGen-LLM at Meta test-a-thons for the Instagram and Facebook platforms. In an evaluation on Reels and Stories products for Instagram, 75% of TestGen-LLM's test cases built correctly, 57% passed reliably, and 25% increased coverage. During Meta's Instagram and Facebook test-a-thons, it improved 11.5% of all classes to which it was applied, with 73% of its recommendations being accepted for production deployment by Meta software engineers. We believe this is the first report on industrial scale deployment of LLM-generated code backed by such assurances of code improvement.
研究动机与目标
- 推动将单元测试改进自动化,以覆盖遗漏的边界情况并提高测试覆盖率,同时保持现有行为不变。
- 引入 Assured Offline LLM-Based Software Engineering (Assured LLMSE) 作为可验证改进的指导框架。
- 描述 TestGen-LLM 系统架构、过滤管道,以及用于评估 LLM 与提示的遥测数据。
- 报道 Meta 内部大规模部署 TestGen-LLM 的经验,包括评估结果和经验教训。
提出的方法
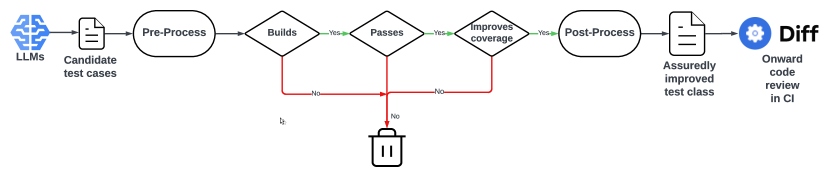
- 使用由 Meta 开发的两种 LLM 的集合来扩展现有的 Kotlin 测试类,添加额外的测试。
- 应用多重筛选管线:(i) 可编译性筛选,确保生成的测试可编译,(ii) 不回归筛选,通过要求测试一致通过来实现,(iii) 覆盖率筛选,确保新增测试能提升覆盖率。
- 提供逐测试用例的保障和可测量的改进差异,以支持持续集成集成。
- 纳入遥测与评估模式,在全面部署前研究 LLM 提示、温度和提示策略。
- 采用 MVP 到全面部署的路径,结合差异时间部署,以最大化相关性和工程师采用率。
- 使用提示策略(extend_coverage、corner_cases、extend_test、statement_to_complete)和 LLM 集成方法以最大化新增的独特测试。
实验结果
研究问题
- RQ1LLMs 能否生成新的单元测试,使其可编译、可靠通过并提高现有测试集的代码覆盖率?
- RQ2AI 生成的测试改进是否在工业规模的生产环境落地,且工程师接受大多数建议?
- RQ3哪些有效的提示策略与配置(LLM 选择、温度、提示)能够实现可靠的测试生成改进?
- RQ4逐测试用例保障如何影响对大型代码库中自动化测试改进的信任与采用?
- RQ5在生产测试工作流中,Assured LLMSE 的实际部署考虑和经验教训有哪些?
主要发现
- 在 Instagram 评估中,75% 的 TestGen-LLM 测试用例构建正确。
- 57% 的测试类至少有一个测试用例能够正确构建并可靠通过。
- 25% 的测试类至少有一个测试用例能够正确构建、可靠通过并提高覆盖率。
- 在 Instagram 的测试马拉松期间,TestGen-LLM 对其应用的所有类提升了 11.5%。
- Meta 工程师接受了 73% 的 TestGen-LLM 测试改进用于生产部署。
- 在三次测试马拉松中,TestGen-LLM 将 196 个测试类在 1,979 个应用类中进行了改进(约10%。)
- 在 Facebook 与 Instagram 的部署中,280 个差异中有 144 被接受,64 被拒绝,61 未评审,11 撤回。
- 该方法实现了可扩展的自动化测试改进,并具备可验证的非回归保障。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。