[论文解读] Automatic acoustic detection of birds through deep learning: the first Bird Audio Detection challenge
该论文报告了一个公共数据挑战,显示深度学习在未见的声学条件下也能实现高通用性的鸟类检测,Top AUC约为88%,在不同数据集上展现出强泛化能力。
Assessing the presence and abundance of birds is important for monitoring specific species as well as overall ecosystem health. Many birds are most readily detected by their sounds, and thus passive acoustic monitoring is highly appropriate. Yet acoustic monitoring is often held back by practical limitations such as the need for manual configuration, reliance on example sound libraries, low accuracy, low robustness, and limited ability to generalise to novel acoustic conditions. Here we report outcomes from a collaborative data challenge showing that with modern machine learning including deep learning, general-purpose acoustic bird detection can achieve very high retrieval rates in remote monitoring data --- with no manual recalibration, and no pre-training of the detector for the target species or the acoustic conditions in the target environment. Multiple methods were able to attain performance of around 88% AUC (area under the ROC curve), much higher performance than previous general-purpose methods. We present new acoustic monitoring datasets, summarise the machine learning techniques proposed by challenge teams, conduct detailed performance evaluation, and discuss how such approaches to detection can be integrated into remote monitoring projects.
研究动机与目标
- 推动在远程声学监测中实现鲁棒、通用的鸟类检测,且不需要物种特异性调参或环境特定校准。
- 从远程监测和众包来源创建多样化的带标注数据集,以测试泛化能力。
- 以共同、无偏的检测任务(用AUC评估)基准化基线与深度学习方法。
- 分析检测器校准与错误类型,为现实世界监测网格的部署提供依据。
提出的方法
- 汇集多源数据集(切尔诺贝利CEZ、Warblr众包、freefield1010、PolandNFC),并为十秒片段标注鸟类存在/不存在标签。
- 定义通用检测任务:将每个10秒片段标注为鸟类存在或不存在,从而实现±10秒内的精确时间定位。
- 向参与者提供开发数据和私有测试数据以防止过拟合,并再提供一个用于泛化测试的独立数据集。
- 基线分类器:smacpy(带高斯混合模型的MFCC)和skfl(在梅尔谱上进行无监督特征学习,使用随机森林)。
- 参与者采用深度学习方法(通常是卷积神经网络),以频谱图(梅尔)输入并进行数据增强;输出为概率分数,用以计算AUC。
- 评估聚焦于对未见条件与站点的泛化,以及通过校准图进行的校准分析。
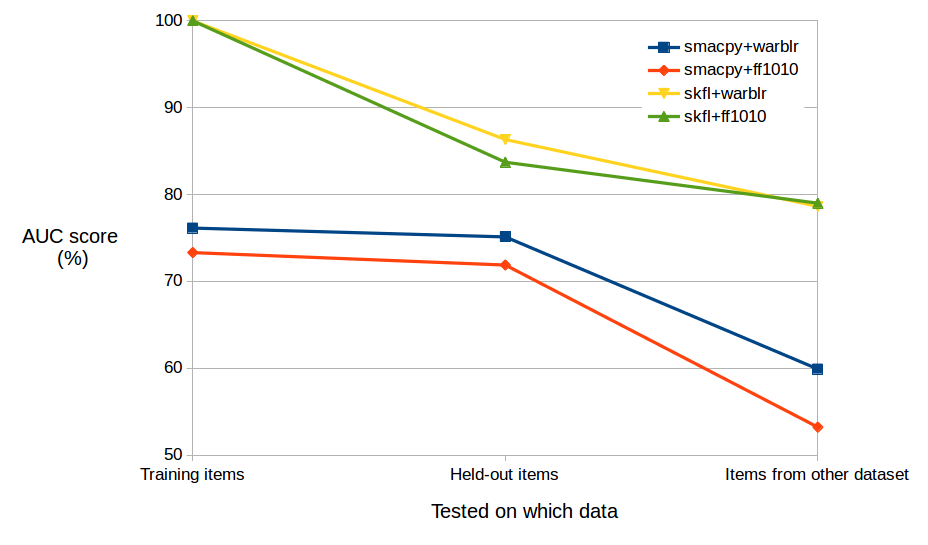
实验结果
研究问题
- RQ1通用、物种无关的检测器是否能够在不进行环境特定调参的情况下实现高鸟类检测性能?
- RQ2检测方法对未见声学环境和数据源的泛化能力如何?
- RQ3基于深度学习的检测器的校准确性有哪些特征?它们在不同站点(如Warblr与Chernobyl)之间有何差异?
- RQ4在具有挑战性的录音中(低信噪比、风噪、昆虫噪声、人类活动)常见的错误来源有哪些,限制检测?
主要发现
- 深度学习方法取得了强劲的性能,大多数团队AUC超过80%,最高分达到88.7% AUC。
- 在重新验证的测试集上,评注一致性很高(AUC 96.7%),表明在重新验证协议下人机判断具有较高的一致性。
- 各站点表现不同,Warblr数据易于检测(AUC>95%),而一些CEZ地点则更具挑战性(领先方法的AUC低至约80%)。
- 检测的校准因数据集而异;一些顶尖方法在已见数据上校准良好,但在未见的CEZ数据上校准较差,凸显校准作为部署的独立考虑因素。
- 大多数提交使用频谱图/梅尔表示,并结合数据增强,基于CNN的深度学习方法主导了前列结果。
- 最强检测器在基于站点的分析中仍显示出稳健的泛化趋势,尽管在按站点评估时确切的排名顺序有所不同。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。