[论文解读] Benchmarking LLM powered Chatbots: Methods and Metrics
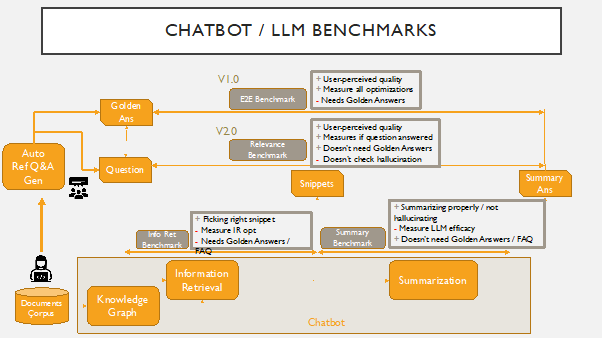
本文提出端到端(End-to-End,E2E)聊天机器人基准测试,该基准通过文本嵌入(USE 和 ST)计算聊天机器人回答与金标准人类回答之间的语义相似性来评估准确性和有用性,并将其与 ROUGE 指标进行对比。
Autonomous conversational agents, i.e. chatbots, are becoming an increasingly common mechanism for enterprises to provide support to customers and partners. In order to rate chatbots, especially ones powered by Generative AI tools like Large Language Models (LLMs) we need to be able to accurately assess their performance. This is where chatbot benchmarking becomes important. In this paper, we propose the use of a novel benchmark that we call the E2E (End to End) benchmark, and show how the E2E benchmark can be used to evaluate accuracy and usefulness of the answers provided by chatbots, especially ones powered by LLMs. We evaluate an example chatbot at different levels of sophistication based on both our E2E benchmark, as well as other available metrics commonly used in the state of art, and observe that the proposed benchmark show better results compared to others. In addition, while some metrics proved to be unpredictable, the metric associated with the E2E benchmark, which uses cosine similarity performed well in evaluating chatbots. The performance of our best models shows that there are several benefits of using the cosine similarity score as a metric in the E2E benchmark.
研究动机与目标
- 促成对由大型语言模型(LLMs)驱动的企业级聊天机器人进行稳健评估。
- 提出一个端到端(E2E)基准,用于衡量聊天机器人答案与专家金标准答案之间的语义相似性。
- 将 E2E 与传统指标如 ROUGE 进行对比评估,并展示基于嵌入的相似性带来的好处。
- 探讨提示工程对 E2E 性能的影响并与 ROUGE 结果进行比较。
提出的方法
- 基于金标准答案与聊天机器人回答的嵌入向量的余弦相似度来定义 E2E 基准。
- 使用两个嵌入库——Universal Sentence Encoder (USE) 和 Sentence Transformer (ST)——来获取句子嵌入。
- 计算金标准答案与聊天机器人答案之间的余弦相似度 S(G,A) = (X_G · X_A) / (|X_G||X_A|)。
- 在同一对答案上将 E2E 结果与 ROUGE 指标(ROUGE-1、ROUGE-2、ROUGE-LCS)进行比较。
- 在一个产品支持聊天机器人上进行评估,并分析基于嵌入的分数与 ROUGE 的相关性。
- 考察提示工程(标准提示与增强提示)对 E2E 和 ROUGE 指标的影响。
实验结果
研究问题
- RQ1使用句子嵌入的余弦相似度的 E2E 基准在 LLM 驱动的聊天机器人中相对于基于 ROUGE 的评估表现如何?
- RQ2基于嵌入的 E2E 分数是否比 ROUGE 分数更能反映提示工程带来的改进?
- RQ3USE 与 ST 嵌入在衡量聊天机器人性能方面的关系是什么?
- RQ4E2E 是否能够区分有意义的改进与评估中的噪声(如随机词)?
- RQ5E2E 基准对不同嵌入模型的敏感度有多高?
主要发现
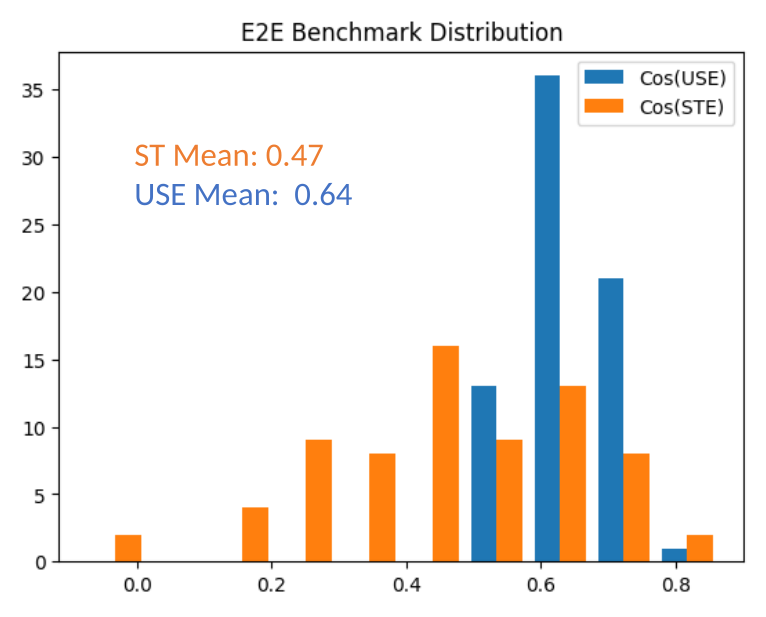
- 使用 USE 的 E2E 平均余弦相似度约为 0.64;使用 ST 的 E2E 在所评估的聊天机器人上约为 0.47。
- USE 基于和 ST 基于的 E2E 结果之间存在强相关性(R^2 约为 0.7)。
- ROUGE 指标与基于嵌入的 E2E 结果相关性有限,且未始终如一地反映提示工程带来的改进。
- 使用 ST 嵌入的 E2E 基准在应用经过设计的提示时显示出更明显的改进,表明对提示设计更敏感。
- 在对随机词进行测试时,E2E 分数降至接近随机,其中 ST 在该情境下胜过 USE。
- 提示工程(增强提示)对 ST 基于 E2E 的结果有显著提升,超过了对 USE 的提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。