[论文解读] BioCLIP: A Vision Foundation Model for the Tree of Life
本论文提出 TreeOfLife-10M,最大的可用于ML的生物图像数据集,以及 BioCLIP,一种在 CLIP 风格的多模态对比学习中利用分类等级来实现对生物界树的零-shot与少-shot分类的视觉基础模型。
Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks and find that BioCLIP consistently and substantially outperforms existing baselines (by 16% to 17% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. https://imageomics.github.io/bioclip has models, data and code.
研究动机与目标
- 创建一个大规模、多样化的生物图像数据集,带有分类标签,以支持基础模型预训练(TreeOfLife-10M)。
- 开发一个视觉基础模型(BioCLIP),利用分类结构来提升对未见分类群的泛化能力。
- 展示在多样化细粒度生物分类任务中的强大零-shot和少-shot性能。
- 研究文本类型(分类名、学名、通用名)如何影响模型泛化。
- 提供内在分析,显示学习到的分层表示与生命之树一致。
提出的方法
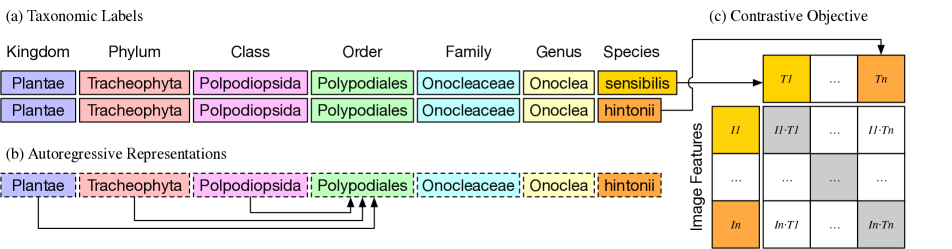
- 通过合并 iNat21、Bioscan-1M 与 Encyclopedia of Life 的图像,并采用标准化的分类等级来整理 TreeOfLife-10M。
- 以 OpenAI CLIP 权重初始化,并在 TreeOfLife-10M 上继续使用 CLIP 的多模态对比目标进行预训练。
- 将分类标签表示为分类名称(扁平化的层级),并在 CLIP 框架中训练模型使图像与这些名称相匹配。
- 尝试混合文本类型(分类名、学名、通用名),以提高推理时的灵活性。
- 在覆盖动物、植物和真菌的10个多样化细粒度数据集上评估零-shot和少-shot性能,包括一个Rare Species测试集。
- 将 BioCLIP 与在 LAION-400M 上训练的 CLIP 和 OpenCLIP 进行比较,并对数据源和文本类型策略进行消融分析。
实验结果
研究问题
- RQ1在 TreeOfLife-10M 上训练的视觉基础模型是否能够泛化到训练数据中未出现的分类群(零-shot),覆盖生命之树?
- RQ2通过 CLIP 风格目标将分类结构编码到标签空间,是否提升细粒度生物分类,尤其是在数据稀缺的情况下?
- RQ3训练中使用的不同文本类型(分类名、学名、通用名)如何影响零-shot和少-shot泛化?
- RQ4数据多样性(TreeOfLife-10M 与 iNat21)对下游性能和对未见分类群的泛化有何影响?
- RQ5BioCLIP 是否学习到反映生命之树的分层表征?这在内在分析中如何体现?
主要发现
- BioCLIP 在十个细粒度生物数据集上,在零-shot 情况下稳定地优于基线(领先约 17–20 个百分点)。
- BioCLIP 实现了强劲的少-shot 增益,在 1-shot 和 5-shot 设置中显著优于 CLIP 和 OpenCLIP。
- 零-shot性能在未见的 Rare Species 上尤为强劲,表明对训练数据中未出现的分类群具有良好泛化能力。
- 内在分析显示 BioCLIP 学习了与生命之树对齐的分层特征结构,从而解释了改进的泛化。
- 在训练中使用分类名显著提高零-shot 精度,相比仅使用学名,混合文本类型也提升了推理时的灵活性。
- TreeOfLife-10M 的多样性,包括来自 EOL 的数据,相比单独使用 iNat21 可显著提升性能。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。