[论文解读] BlackMamba: Mixture of Experts for State-Space Models
黑曼巴 将 Mamba 状态空间块 与 Mixture-of-Experts 路由 相结合,以实现线性时间生成和降低训练/推理 FLOPs,开源模型规格为 340M/1.5B 和 630M/2.8B,在 300B 标记数据上训练。
State-space models (SSMs) have recently demonstrated competitive performance to transformers at large-scale language modeling benchmarks while achieving linear time and memory complexity as a function of sequence length. Mamba, a recently released SSM model, shows impressive performance in both language modeling and long sequence processing tasks. Simultaneously, mixture-of-expert (MoE) models have shown remarkable performance while significantly reducing the compute and latency costs of inference at the expense of a larger memory footprint. In this paper, we present BlackMamba, a novel architecture that combines the Mamba SSM with MoE to obtain the benefits of both. We demonstrate that BlackMamba performs competitively against both Mamba and transformer baselines, and outperforms in inference and training FLOPs. We fully train and open-source 340M/1.5B and 630M/2.8B BlackMamba models on 300B tokens of a custom dataset. We show that BlackMamba inherits and combines both of the benefits of SSM and MoE architectures, combining linear-complexity generation from SSM with cheap and fast inference from MoE. We release all weights, checkpoints, and inference code open-source. Inference code at: https://github.com/Zyphra/BlackMamba
研究动机与目标
- 激励 将状态空间模型 (SSMs) 与 mixture-of-experts (MoE) 相结合,以提升相较于密集 Transformer 的效率与可扩展性。
- 通过用 Mamba 块替代注意力并为 MLP 组件整合 MoE 路由,设计并实现 BlackMamba。
- 在性能、训练 FLOPs 和推理效率方面,实证评估 BlackMamba 相对于 Mamba 与 Transformer 基线。
- 展示大规模 BlackMamba 变体的可扩展训练,并公开模型权重与推理代码以供社区使用。
提出的方法
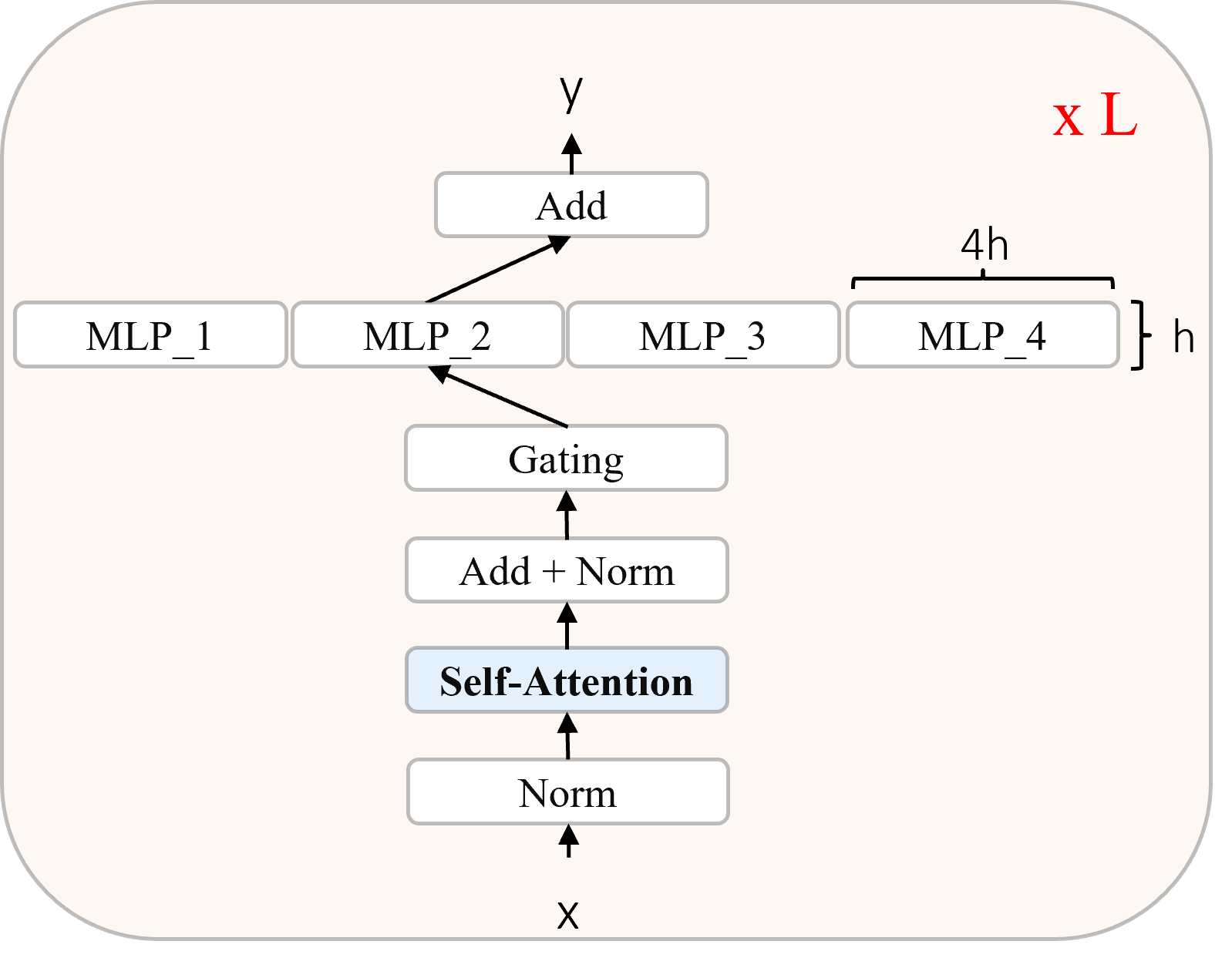
- 将 BlackMamba 介绍为交替的无注意力 Mamba 块与路由的 MoE 层的堆叠架构。
- 使用输入相关门控,使 Eq. (4) 中的 SSM 矩阵 A、B、C 依赖于 x(t)。
- 使用基于 Sinkhorn 的优化器的 top-1 路由,在每层 8 个 MoE 专家之间平衡负载。
- 在 1.8–2.0 万亿标记的混合数据集上训练两种模型尺寸(340M/1.5B 和 630M/2.8B 前向/总参数)。
- 使用 bf16 精度,基于 Megatron-LM 框架训练;在每个 MoE 块中激活 8 个专家;禁用偏置;专家 MLP 使用 SwiGLU。
- 提供推理代码和符合 Apache 2.0 的开源检查点。
实验结果
研究问题
- RQ1将 Mamba 风格的状态空间块与 MoE 路由结合,是否在大规模下仍能实现具有竞争力的语言建模性能,同时降低训练和推理 FLOPs?
- RQ2BlackMamba 模型在生成延迟和长上下文处理方面,与密集 Transformer 和纯 Mamba 基线相比如何?
- RQ3MoE 路由在 BlackMamba 中随深度和训练时间的变化如何,Sinkhorn 路由初始化对收敛的影响是什么?
- RQ4在一个大规模多数据集预训练语料上训练 BlackMamba 变体时,数据与参数的高效性如何?
主要发现
- BlackMamba 在评估中具有竞争性表现,训练 FLOPs 明显更低,推理更快,相较于密集 Transformer 和纯 Mamba 基线。
- BlackMamba 的推理时延,特别是在较长序列长度时,显著快于标准 Transformer,且与可比 MoE Transformer 相当,因为线性时间的 SSM 生成和稀疏 MoE 路由的结合。
- 大多数层在 Sinkhorn 路由下呈现良好平衡的专家利用率,尽管最后几层出现初现的专业化/失衡模式,需进一步研究。
- 两种开源 BlackMamba 配置(340M/1.5B 与 630M/2.8B)在 300B 标记上训练,并发布了权重和推理代码,供社区使用。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。