[论文解读] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
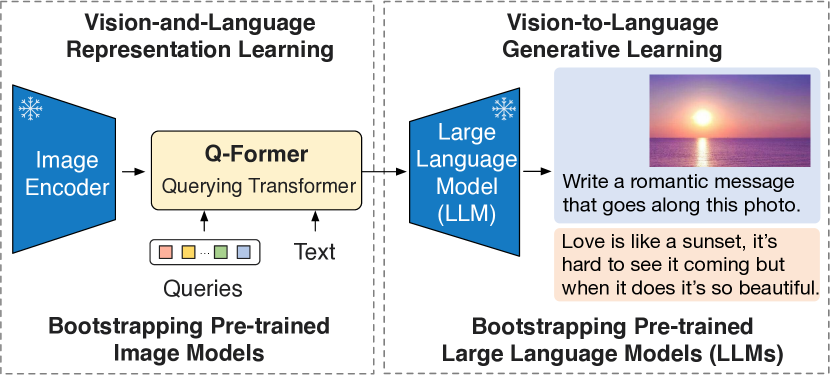
BLIP-2 利用冻结的预训练图像编码器和冻结的大语言模型,通过一个轻量级的 Querying Transformer,在零样本和指令式图像到文本生成方面实现强劲性能,且待训练参数大幅减少。
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
研究动机与目标
- 通过冻结单模态模型并使用一个轻量级的 Q-Former 来桥接模态,降低视觉-语言预训练的成本。
- 通过两阶段预训练来学习跨模态对齐:从冻结的图像编码器进行表征学习,以及从冻结的 LLM 进行生成学习。
- 展示零样本指令化的图像到文本生成以及更广泛的 VLP 能力,并提高效率。
- 表明 BLIP-2 可以利用视觉与语言模型的进展,在更少的可训练参数下实现强结果。
提出的方法
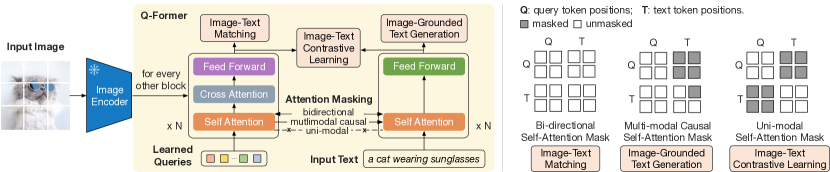
- 提出 Q-Former,一个带有可学习查询的小型 Transformer,连接冻结的图像编码器和冻结的 LLM。
- 阶段1:使用冻结的图像编码器和模态屏蔽注意力,在 ITC、ITG 和 ITM 目标下进行视觉-语言表征学习。
- 阶段2:通过将 Q-Former 的输出投射到 LLM,并使用语言模型损失(基于解码器的 LLM)或前缀语言建模(编码器-解码器 LLM)进行训练,完成从视觉到语言的生成学习。
- 在保持 LLM 冻结的同时,对 BLIP-2 进行下游任务(VQA、 captioning、检索)的微调,并更新 Q-Former 与图像编码器。
- 使用 CapFilt+curation 以及 in-batch negatives,在来自多源的 129M 图文对上进行训练。
实验结果
研究问题
- RQ1能否通过冻结的图像编码器和冻结的的大型语言模型构建的视觉-语言预训练框架,在仅使用一个轻量级的桥接模块的情况下达到最先进的性能?
- RQ2如何通过一个最小化的查询机制(Q-Former)在不更新大骨干网络的情况下实现有效的跨模态对齐?
- RQ3在使用冻结的单模态模型时,零样本指令化的图像到文本生成有哪些新兴能力?
- RQ4就可训练参数量和计算量而言,BLIP-2 的效率与端到端的大型视觉-语言预训练方法相比如何?
主要发现
- BLIP-2 在零样本视觉-语言任务上取得强劲表现,使用的可训练参数显著低于端到端方法(188M),在零样本 VQAv2 上比 Flamingo80B 高出 8.7%。
- 两阶段预训练(表征学习和从视觉到语言的生成)使冻结的图像编码器和冻结的 LLM 之间实现有效桥接。
- BLIP-2 支持指令化的零样本图像到文本生成,从而实现如视觉知识推理和视觉对话等任务。
- 该方法展示了计算效率,例如单台 16-A100 (40G) 机器即可在几天内完成大型变体的预训练步骤。
- BLIP-2 的结果表明,更大的视觉编码器和更大的 LLM 可以在 VQA、 captioning 和 retrieval 任务上持续提升性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。