[论文解读] BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
BLIP-Diffusion 引入了一个预训练的多模态主体表示,用于实现零-shot和少样本主体驱动文本到图像生成,具备高效微调,并与 ControlNet 和 prompt-to-prompt 编辑兼容。
Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
研究动机与目标
- 推动高效、可扩展的主体驱动生成,在不进行大量微调的情况下保持主体保真。
- 开发与文本对齐、用于引导扩散模型的预训练通用主体表示。
- 实现对主体的零-shot 与少量-shot 个性化,显著减少微调步骤。
提出的方法
- 两阶段预训练:(1) 利用 BLIP-2 风格的编码器进行多模态表示学习,使图像特征与文本对齐;(2) 主体表示学习,使扩散模型从视觉特征学习生成主体的再现。
- 使用 BLIP-2 多模态编码器从主体图像和类别文本生成文本对齐的主体表示。
- 通过投影 BLIP-2 输出并与文本提示拼接,将一个软视觉主体提示注入扩散模型(模板如 “[text prompt], the [subject text] is [subject prompt]”)。
- 在微调期间冻结扩散模型的文本编码器以防止过拟合;以较少的步骤(40-120)对主体特定生成进行微调。
- 通过操作跨注意力映射,实现与 ControlNet 的结构控制和 prompt-to-prompt 风格编辑的模块化扩展。
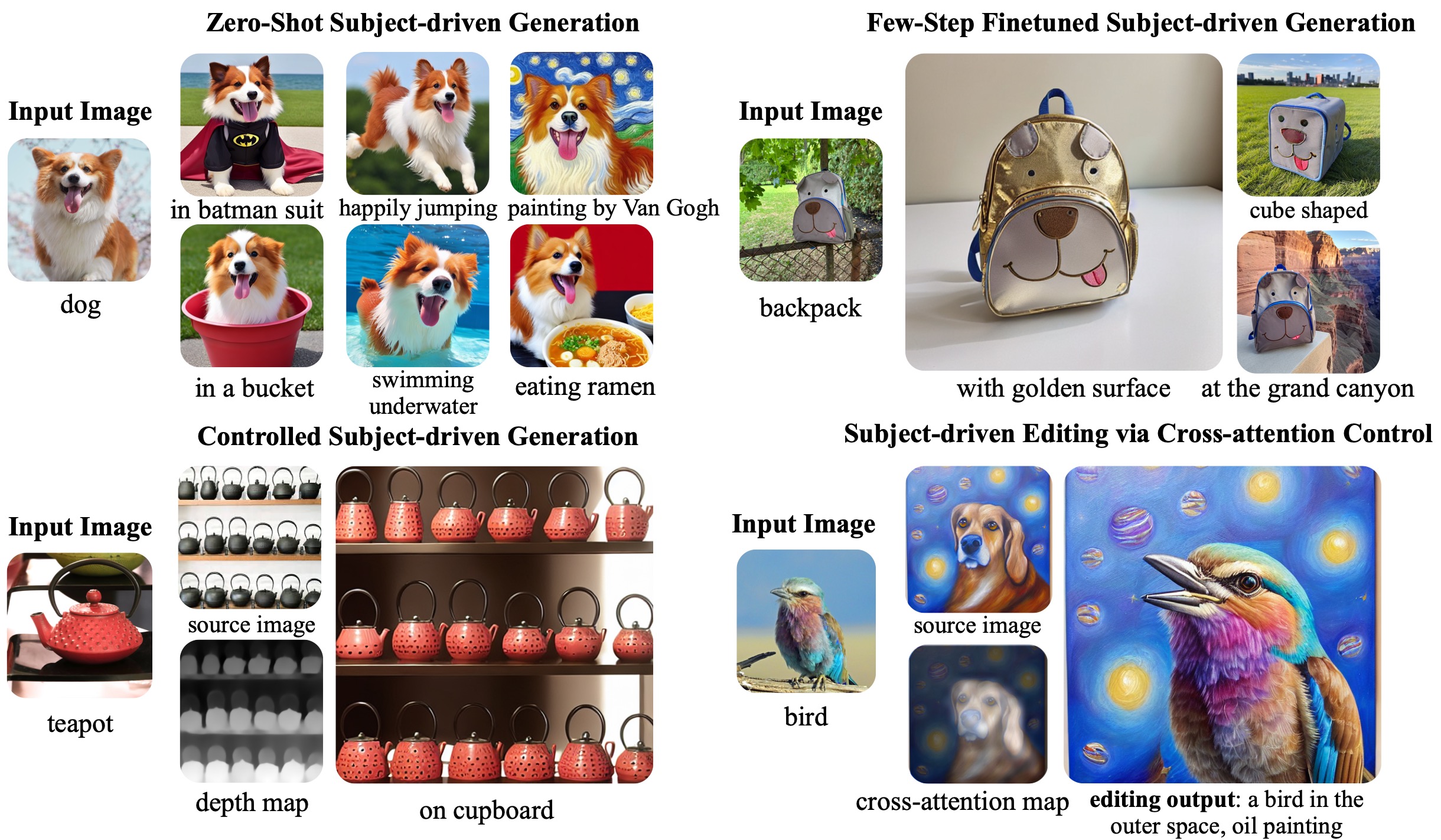
实验结果
研究问题
- RQ1能否通过一个预训练的多模态主体表示来实现高保真度的零-shot 主体驱动生成?
- RQ2与先前方法相比,需要多少微调步骤来针对新主体进行个性化?
- RQ3在不重新训练基础模型的前提下,主体表示能否与现有的编辑/结构控制技术(ControlNet、prompt-to-prompt)有效组合?
- RQ4在提供多模态控制的同时,模型是否保留扩散模型的核心能力?
- RQ5两阶段预训练对主体视觉特征与文本提示之间对齐的影响是多少?
主要发现
| Methods | DINO | CLIP-I | CLIP-T |
|---|---|---|---|
| Real Images (Oracle) | 0.774 | 0.885 | - |
| Textual Inversion | 0.569 | 0.780 | 0.255 |
| Re-Imagen | 0.600 | 0.740 | 0.270 |
| DreamBooth | 0.668 | 0.803 | 0.305 |
| – 100 fine-tuning steps | 0.396 | 0.698 | 0.322 |
| – 300 fine-tuning steps | 0.500 | 0.733 | 0.319 |
| Ours (ZS) | 0.594 (±0.004) | 0.779 (±0.003) | 0.300 (±0.002) |
| Ours (FT, avg. < 80 steps) | 0.670 (±0.004) | 0.805 (±0.002) | 0.302 (±0.001) |
- BLIP-Diffusion 实现了具高主体保真度的零-shot 主体驱动生成。
- 微调需要 40-120 步,比 DreamBooth 等方法快最多 20 倍。
- 结合 ControlNet 或 prompt-to-prompt 时,模型支持带有主体特定视觉的结构可控生成与编辑。
- 定量指标显示其性能与 Textual Inversion 和 Re-Imagen 相当甚至优秀,在较少微调的情况下也优于 DreamBooth。
- 消融研究显示多模态预训练和冻结策略对在利用主体表示时维持文本控制的重要性。
- 主体表示同时捕捉局部和整体主体特征,实现多样化编辑和风格迁移能力。
![Figure 2: Illustration of the two-staged pre-training for BLIP-Diffusion. Left : in the multimodal representation learning stage, we follow prior work [ 12 ] and pretrain BLIP-2 encoder to obtain text-aligned image representation. Right : in the subject representation learning stage, we synthesize i](https://ar5iv.labs.arxiv.org/html/2305.14720/assets/x1.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。