[论文解读] BurstGPT: A Real-world Workload Dataset to Optimize LLM Serving Systems
介绍 BurstGPT,第一个真实世界的 LLM 服务工作负载跟踪,以及用于在突发负载下评估和优化 LLM 服务系统的基准套件。
Serving systems for Large Language Models (LLMs) are often optimized to improve quality of service (QoS) and throughput. However, due to the lack of open-source LLM serving workloads, these systems are frequently evaluated under unrealistic workload assumptions. Consequently, performance may degrade when systems are deployed in real-world scenarios. This work presents BurstGPT, an LLM serving workload with 10.31 million traces from regional Azure OpenAI GPT services over 213 days. BurstGPT captures LLM serving characteristics from user, model and system perspectives: (1) User request concurrency: burstiness variations of requests in Azure OpenAI GPT services, revealing diversified concurrency patterns in different services and model types. (2) User conversation patterns: counts and intervals within conversations for service optimizations. (3) Model response lengths: auto-regressive serving processes of GPT models, showing statistical relations between requests and their responses. (4) System response failures: failures of conversation and API services, showing intensive resource needs and limited availability of LLM services in Azure. The details of the characteristics can serve multiple purposes in LLM serving optimizations, such as system evaluation and trace provisioning. In our demo evaluation with BurstGPT, frequent variations in BurstGPT reveal declines in efficiency, stability, or reliability in realistic LLM serving. We identify that the generalization of KV cache management, scheduling and disaggregation optimizations can be improved under realistic workload evaluations. BurstGPT is publicly available now at https://github.com/HPMLL/BurstGPT and is widely used to develop prototypes of LLM serving frameworks in the industry.
研究动机与目标
- 突出真实世界 LLM 服务工作负载的特征,以指引系统设计与容量规划。
- 量化真实世界 GPT 服务(ChatGPT 和 GPT-4)中的突发性、并发模式和故障率。
- 开发一个可扩展的基准套件,反映 BurstGPT 的工作负载模式,以评估服务系统。
- 提供见解,使 LLM 服务实现弹性资源管理和改进的 QoS。
提出的方法
- 在校园环境中,收集并分析来自 ChatGPT 和 GPT-4 API 及会话服务的实时工作负载跟踪,持续两个月。
- 表征 LLM 工作负载的时间(周期性/非周期性)和空间(请求/响应长度)模式。
- 使用 Gamma 分布来建模突发性,并证明其对 GPU 内存和服务可靠性的影响。
- 开发一个镜像的 BurstGPT 基准测试,能够扩展到不同的系统规模并反映观察到的工作负载模式。
- 原型化一个工作负载生成器,包含提示词池、并发生成器和基于 HTTP 的推理驱动,用于评估 LLM 服务系统。
- 在 BurstGPT 风格的工作负载下评估 vLLM 在 Llama-2-chat 模型上的性能,以研究延迟、吞吐量和故障行为。
实验结果
研究问题
- RQ1真实世界的 LLM 服务工作负载在时间和空间上有哪些特征?
- RQ2突发性如何影响 LLM 服务系统的可靠性和 GPU 内存使用?
- RQ3基于 BurstGPT 的基准套件是否能在不同规模上真实地评估服务系统?
- RQ4在 BurstGPT 风格的突发负载下,领先的 LLM 服务框架(vLLM)的表现如何?
主要发现
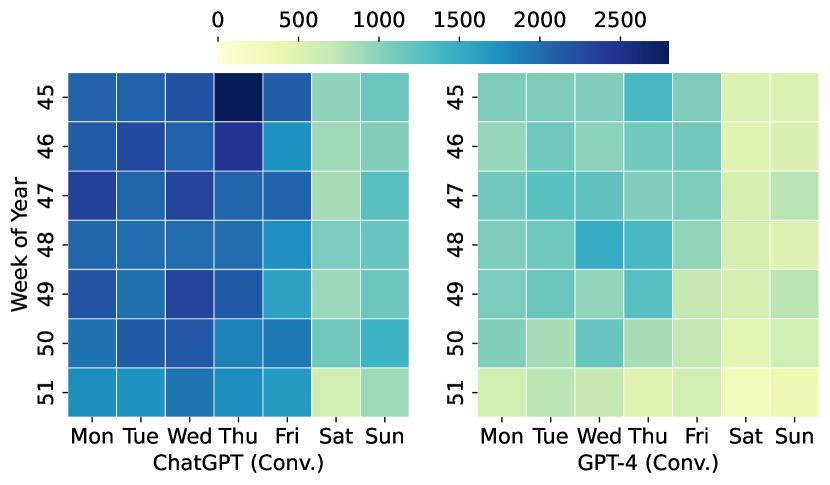
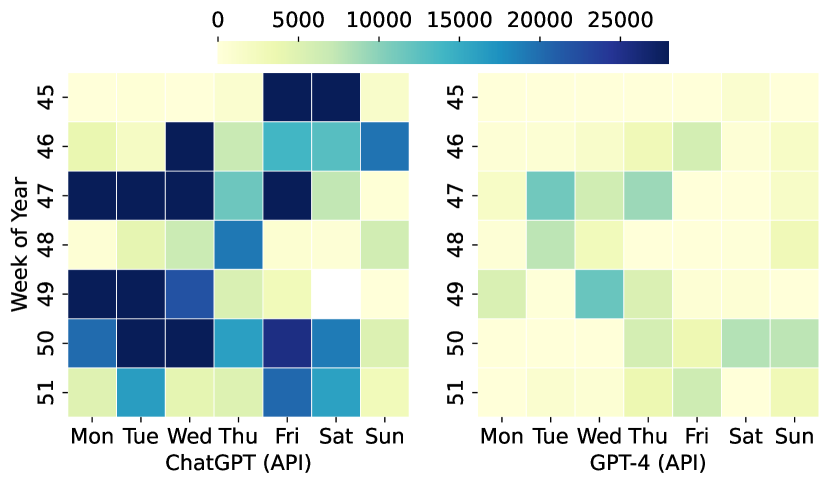
- LLM 工作负载中的突发性表现出周期性和非周期性模式,随服务类型(会话 vs API)和模型(ChatGPT vs GPT-4)而异。
- 会话服务表现出更规律的日常模式,而 API 服务呈现不规则、突发的流量且波动性更高。
- 请求长度遵循 Zipf 类分布,而响应长度显示出模型相关,通常是双峰或长尾分布。
- 来自突发工作负载的 GPU 内存压力与更高的故障率相关,表明内存瓶颈是关键的可靠性风险。
- BurstGPT 基准测试可以模拟真实世界的突发性,并揭示现有系统在短期突发情况下的性能下降。
- 在 BurstGPT 风格工作负载下对 vLLM 的评估显示对突发性和内存管理的敏感性,影响延迟和成功率。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。