[论文解读] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models
本论文提出 Chain-of-Symbol(CoS)提示,通过对空间关系的 condensed 符号表示来引导大语言模型的规划,在三个空间任务和一个空间问答基准上优于 Chain-of-Thought(CoT),同时减少输入令牌数量。
In this paper, we take the initiative to investigate the performance of LLMs on complex planning tasks that require LLMs to understand a virtual spatial environment simulated via natural language and act correspondingly in text. We propose a benchmark named Natural Language Planning and Action (Natala) composed of a set of novel tasks: Brick World, NLVR-based Manipulations, and Natural Language Navigation. We found that current popular LLMs such as ChatGPT still lack abilities in complex planning. This arises a question -- do the LLMs have a good understanding of the environments described in natural language, or maybe other alternatives such as symbolic representations are neater and hence better to be understood by LLMs? To this end, we propose a novel method called CoS (Chain-of-Symbol Prompting) that represents the complex environments with condensed symbolic spatial representations during the chained intermediate thinking steps. CoS is easy to use and does not need additional training on LLMs. Extensive experiments indicate that CoS clearly surpasses the performance of the Chain-of-Thought (CoT) Prompting in all three planning tasks with even fewer tokens used in the inputs compared with CoT on ChatGPT and InstructGPT. The performance gain is strong, by up to 60.8% accuracy (from 31.8% to 92.6%) on Brick World for ChatGPT. CoS also reduces the number of tokens in the prompt obviously, by up to 65.8% of the tokens (from 407 to 139) for the intermediate steps from demonstrations on Brick World. Code and data available at: https://github.com/hanxuhu/chain-of-symbol-planning
研究动机与目标
- 评估在自然语言描述的复杂空间理解与规划任务中对大语言模型的表现。
- 评估符号表示是否能在空间任务中超越自然语言中间步骤(CoT)的表现。
- 提出并验证 CoS 提示作为一种训练-free 的方法,以减少提示长度。
- 分析 CoS 在模型、语言和符号选择上的鲁棒性。
提出的方法
- 提出 Chain-of-Symbol(CoS)提示,用 condensed 符号表示空间关系来替代自然语言中间步骤。
- 自动生成 CoT 演示、纠错,并通过用符号替换空间关系并去除非关键文本,将其转换为 CoS。
- 使用带 CoS 演示的少量示例提示,引导 LLM 进行三个空间规划任务。
- 评估在 ChatGPT(gpt-3.5-turbo)和 Text-Davinci-003 上的兼容性和性能,比较零样本 CoT、少量示例 CoT 和少量示例 CoS 基线。
- 衡量规划任务的准确率、精确率、召回率(以及对某些任务的基于 LCS 的相似度)和空间问答的准确率。
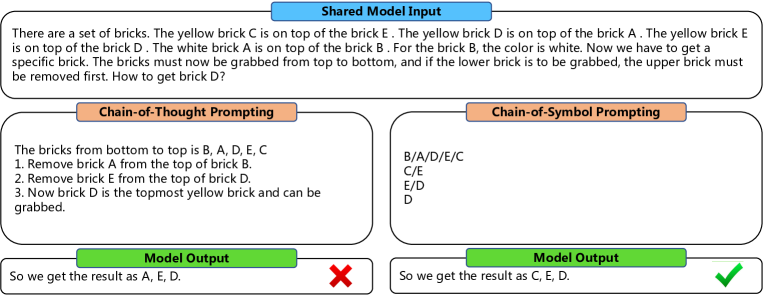
实验结果
研究问题
- RQ1符号化的空间关系表示是否能在文本描述的环境中提升 LLM 的规划能力,相较于自然语言的 CoT?
- RQ2CoS 提示是否能跨不同任务、语言和模型类型实现泛化?
- RQ3相比 CoT,CoS 对令牌效率和推理成本有何影响?
- RQ4CoS 的收益是否对符号选择和任务复杂度具鲁棒性?
主要发现
- CoS 在 Brick World、基于 NLVR 的操控和自然语言导航三个任务中对 CoT 的性能提升具有一致性。
- 在 Brick World 1D Shuffle Label 的 1D 场景中,CoS 的准确率达到 92.6%,相较基线 CoT(31.8%)提升 60.8 点。
- CoS 能显著减少中间步骤的令牌数量(例如 Brick World 1D 从 407 降至 139 个令牌)。
- CoS 在语言多样性(中文显示相较于 CoT 的性能提升)和不同符号选择上具有鲁棒性,其中逗号是一个有效的选择。
- 在 SPARTUN 数据集上,对 GPT-3.5-Turbo 和 GPT-4,CoS 的准确率高于 CoT,且中间令牌更少。
- 相较于 CoT,CoS 在若干试验中的输出波动性较低(标准差较小)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。