[论文解读] Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
本文提出 LLM-Augmenter,是一个即插即用的系统,通过外部知识增强固定的 LLM、通过自动反馈进行迭代提示修订,以及一个可训练策略在保持流畅性的同时减少幻觉。它在信息检索对话和开放领域 Wiki 问答中验证了有效性。
Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
研究动机与目标
- 动机:在执行关键任务的大型语言模型中减少幻觉和知识空白。
- 提出一个即插即用架构(LLM-Augmenter),用外部知识来支撑 LLM 的回答。
- 通过自动反馈实现迭代提示改进,以提升回答质量。
- 探索在固定 LLM 下不进行全面微调的情况下,训练策略以使策略和模块有效运行。
提出的方法
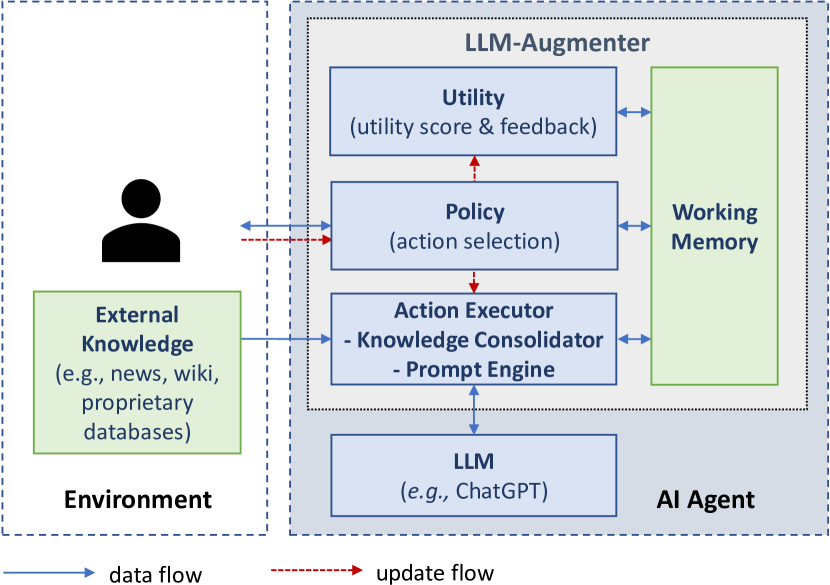
- 提出 LLM-Augmenter 作为一个由可插拔模块组成的系统,利用外部知识和自动反馈来增强固定的 LLM。
- 将人机对话建模为一个马尔可夫决策过程,以引导模块交互。
- 实现知识整合器,用以检索并串联外部证据,以及用于定位 grounding 的 Evidence Chainer。
- 使用 Prompt Engine 生成融入证据和反馈以指导 LLM 的提示。
- 开发实用性模块,用来生成分数和反馈,指导提示修订。
- 通过 REINFORCE 训练策略(pi),以最大化基于 grounding 和有用性的奖励。
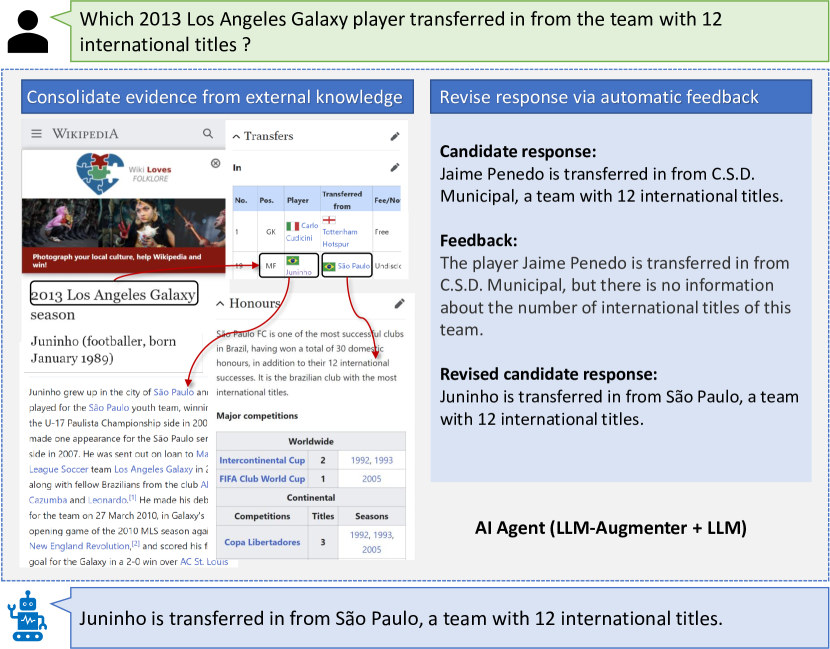
实验结果
研究问题
- RQ1在固定的 LLM 中,外部知识 grounding 是否能在不牺牲流畅性的前提下减少幻觉?
- RQ2自动反馈和迭代提示修订是否能改善回答的事实 grounding 与有用性?
- RQ3在决定何时使用外部知识来源时,可训练策略的效果如何?
- RQ4知识整合和反馈对开放领域 Wiki 问答和对话任务有何影响?
主要发现
- 与仅使用 ChatGPT 相比,LLM-Augmenter 在新闻对话和客户服务任务上显著改善 grounding、并减少幻觉。
- 使用黄金知识会带来较大性能提升,强调了面向任务的外部知识在 grounding 的价值。
- 自动反馈和证据整合共同显著提升 KF1 等相关指标,相较于基线。
- 带有知识整合的可训练策略在 grounding 方面优于无知识整合和自问变体,在始终使用知识的情况下的效率也更高。
- 在 Wiki QA 中,基于 CORE 的整合结合反馈显著提升 recall 和 F1,相较于原始 DPR 证据和闭卷 ChatGPT。
- 人工评估显示,在客户服务场景中,LLM-Augmenter 比单独的 ChatGPT 更有用且更具人性化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。