[论文解读] ChipNeMo: Domain-Adapted LLMs for Chip Design
ChipNeMo 展示了适用于芯片设计的领域自适应大模型,通过结合领域自适应预训练、定制分词器、面向领域的监督微调以及检索增强生成,在工程聊天机器人、EDA 脚本生成和错误摘要任务中优于通用大模型,能够在相似性能下实现高达 5x 的参数削减。
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: domain-adaptive tokenization, domain-adaptive continued pretraining, model alignment with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our evaluations demonstrate that domain-adaptive pretraining of language models, can lead to superior performance in domain related downstream tasks compared to their base LLaMA2 counterparts, without degradations in generic capabilities. In particular, our largest model, ChipNeMo-70B, outperforms the highly capable GPT-4 on two of our use cases, namely engineering assistant chatbot and EDA scripts generation, while exhibiting competitive performance on bug summarization and analysis. These results underscore the potential of domain-specific customization for enhancing the effectiveness of large language models in specialized applications.
研究动机与目标
- 展示领域自适应大模型在工业芯片设计任务中的有效性。
- 展示技术:领域自适应预训练、领域特定分词器、监督微调以及检索增强生成。
- 在三个用例上进行评估:工程助理聊天机器人、EDA 脚本生成,以及错误/缺陷摘要分析。
- 评估领域自适应如何影响模型大小、成本和性能,相对于基础的 LLaMA2 模型。
提出的方法
- 通过对 LLaMA2 7B/13B 应用领域自适应预训练 (DAPT),使用领域特定数据(内部芯片设计文本和公开来源)来构建 ChipNeMo 基础模型。
- 用领域特定令牌对分词器进行适配,以提高分词效率(新增约 9K 个新令牌)。
- 结合通用对话数据(128k 条样本)和领域特定指令数据(≈1.1k 条样本),应用监督微调(SFT)。
- 重新训练一个领域自适应的检索模型并整合检索增强生成(RAG),以使回答基于域内文本。
- 使用 AutoEval 风格的领域基准、人类评定和代码生成指标在三个应用中进行评估。
- 将 ChipNeMo 与通用 LLMs(例如 LLaMA2-13B-Chat*、LLaMA2-70B-Chat)对比,并分析缩放、分词与检索等因素的影响。
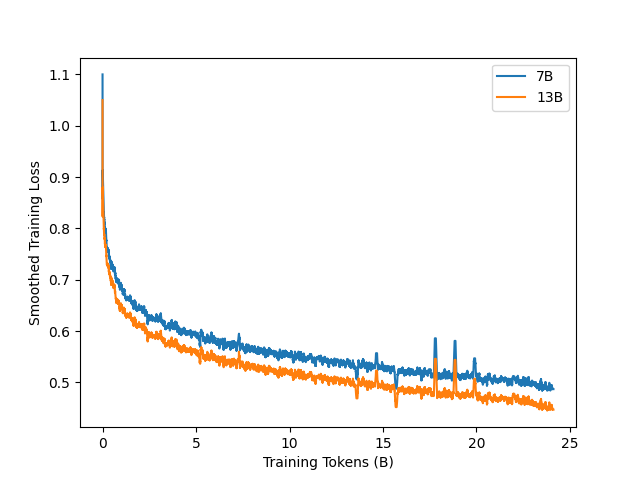
实验结果
研究问题
- RQ1领域自适应的 LLM 在芯片设计任务中的表现与通用 LLM 相比如何?
- RQ2领域自适应预训练、领域特定分词器以及领域对齐的 SFT 对任务性能的影响是什么?
- RQ3检索增强生成是否能提高芯片设计场景中域内响应的准确性和依据性?
- RQ4应用 ChipNeMo 技术时,在模型大小、训练成本和推理效率方面有哪些权衡?
- RQ5在领域自适应下,三个评估应用(工程助理聊天机器人、EDA 脚本生成、错误/缺陷摘要分析)的表现如何?
主要发现
- 领域自适应的 ChipNeMo 模型在多个领域基准和跨三个任务的人类评估中优于通用 LLM。
- 工程助手聊天机器人在专家评估中得分 7.4/10;EDA 脚本生成的正确率超过 50%;专家对缺陷摘要/分配任务的评分为 4–5/7。
- 领域自适应缩小了最先进的 70B 模型与 13B 模型之间的差距,在上下文密集任务中实现高达 5x 的参数削减,同时性能相近或更好。
- 定制的领域分词器在不降低应用有效性的前提下,减少 DAPT 的令牌数最多达到 3.3%。
- 领域自适应检索模型较预训练检索器将检索命中率提升 30%,提升 RAG 性能。
- 使用领域数据进行检索增强显著提升了对 RAG 启用模型的人类评估分数。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。