[论文解读] Controlled Text Generation with Natural Language Instructions
论文介绍 InstructCTG,这是一个训练时框架,将生成约束口述为自然语言指令并对预训练模型进行微调,从而实现灵活、无需解码、基于指令的受控文本生成,且对未见约束具有强大的少样本泛化能力。
Large language models generate fluent texts and can follow natural language instructions to solve a wide range of tasks without task-specific training. Nevertheless, it is notoriously difficult to control their generation to satisfy the various constraints required by different applications. In this work, we present InstructCTG, a controlled text generation framework that incorporates different constraints by conditioning on natural language descriptions and demonstrations of the constraints. In particular, we first extract the underlying constraints of natural texts through a combination of off-the-shelf NLP tools and simple heuristics. We then verbalize the constraints into natural language instructions to form weakly supervised training data. By prepending natural language descriptions of the constraints and a few demonstrations, we fine-tune a pre-trained language model to incorporate various types of constraints. Compared to existing search-based or score-based methods, InstructCTG is more flexible to different constraint types and has a much smaller impact on the generation quality and speed because it does not modify the decoding procedure. Additionally, InstructCTG allows the model to adapt to new constraints without re-training through the use of few-shot task generalization and in-context learning abilities of instruction-tuned language models.
研究动机与目标
- 说明需要在解码时约束之外控制大型语言模型输出的动机。
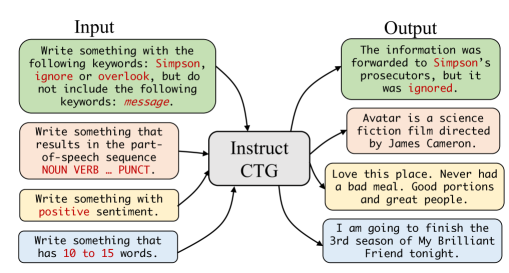
- 提出一种训练时的指令微调方法,使用对约束的自然语言口述。
- 通过给句子标注潜在约束并将其口述为指令,合成一个弱监督训练语料库。
- 展示对约束的高满足度与流畅性,以及对未见约束与小样本场景的泛化能力。
提出的方法
- 通过自动推断自然句子的词汇、句法、语义、风格和长度约束,合成一个大规模弱监督训练语料库。
- 将每个约束口述为自然语言指令,并将其与目标句拼接形成训练对。
- 在扩增语料上对预训练的指令微调模型(T0-11B)进行微调。
- 通过上下文学习引入多次约束演示,以实现对未见约束的少样本泛化。
- 通过将任务提示与约束口述组合(如改写与问题生成)将方法扩展到条件文本生成。
- 通过用“and.”将口述的约束连接起来,实现约束的组合。
- 在推理时保持标准解码过程,不修改解码器。
实验结果
研究问题
- RQ1自然语言约束的口述是否能像解码时约束一样有效地引导生成?
- RQ2用弱监督约束数据进行的指令微调在未见约束(零-shot和少样本)中的迁移能力有多强?
- RQ3该方法是否能泛化到条件生成任务以及多约束的拼接?
- RQ4演示和多模板对已见/未见约束的约束满足度与流畅性有何影响?
主要发现
- InstructCTG 在词汇、句法、语义、风格和长度约束方面,达到与基线同等或更好的约束满足度。
- 该方法比若干基于约束的解码方法获得更高的流畅性分数和更快的生成速度。
- InstructCTG 在有演示的少样本设置下对未见约束表现出强泛化能力。
- 该方法对条件生成任务的扩展效果良好,并支持多约束的组合。
- 少量演示(如5个)在性能与效率之间提供了有利的权衡。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。