[论文解读] Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
引入 SR3+,一种基于扩散的盲(out-of-distribution)图像超分辨率模型,通过将高阶退化与噪声条件增强相结合,在大规模数据集上训练并在 RealSR/DRealSR 上进行零-shot 测试,达到最先进的结果。
Diffusion models have shown promising results on single-image super-resolution and other image- to-image translation tasks. Despite this success, they have not outperformed state-of-the-art GAN models on the more challenging blind super-resolution task, where the input images are out of distribution, with unknown degradations. This paper introduces SR3+, a diffusion-based model for blind super-resolution, establishing a new state-of-the-art. To this end, we advocate self-supervised training with a combination of composite, parameterized degradations for self-supervised training, and noise-conditioing augmentation during training and testing. With these innovations, a large-scale convolutional architecture, and large-scale datasets, SR3+ greatly outperforms SR3. It outperforms Real-ESRGAN when trained on the same data, with a DRealSR FID score of 36.82 vs. 37.22, which further improves to FID of 32.37 with larger models, and further still with larger training sets.
研究动机与目标
- 在退化未知的实际场景中,推动鲁棒的盲单图像超分辨率。
- 开发在分布外输入上仍然有效的基于扩散的模型。
- 利用带有复合退化和噪声条件增强的自监督训练以提升泛化性。
- 证明增加模型规模和训练数据会带来显著提升。
提出的方法
- 使用基于卷积 UNet 的扩散模型(类似 SR3+)用于条件式超分辨率。
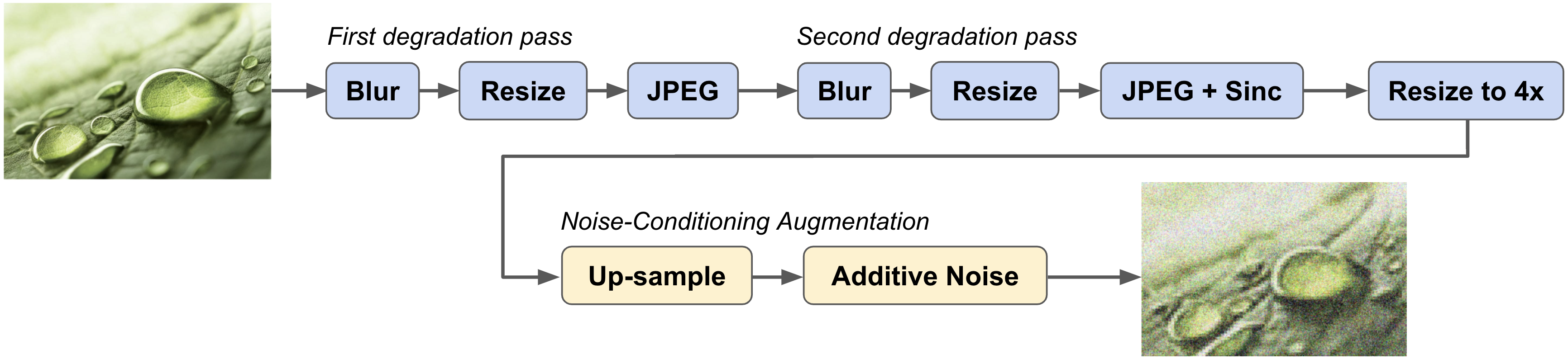
- 在训练中应用高阶、参数化的退化以模拟现实世界的损坏。
- 引入噪声条件增强以提升鲁棒性并实现测试时条件调控。
- 在大规模数据集上训练(DF2K+OST,最多61M张图像)以提升性能。
- 使用 RealSR 与 DRealSR 的零-shot 测试进行评估,采用 FID、PSNR 和 SSIM 指标。
实验结果
研究问题
- RQ1基于扩散的模型能否在真实世界退化下实现盲超分辨率的最先进性能?
- RQ2高阶退化与噪声条件增强是否协同提升对分布外输入的鲁棒性?
- RQ3模型规模和训练数据规模如何影响 SR3+ 在 RealSR/DRealSR 基准上的性能?
- RQ4盲超分中感知保真度(FID)与基于参考的度量(PSNR/SSIM)之间的权衡是什么?
- RQ5SR3+ 在不同数据集和图像内容(如文本密集型图像)下的零-shot 设置是否鲁棒?
主要发现
| Model | FID(10k) RealSR ↓ | FID(10k) DRealSR ↓ | PSNR RealSR ↑ | PSNR DRealSR ↑ | SSIM RealSR ↑ | SSIM DRealSR ↑ |
|---|---|---|---|---|---|---|
| Real-ESRGAN | 34.21 | 37.22 | 25.14 | 25.85 | 0.7279 | 0.7808 |
| SR3+ (40M, DF2K + OST) | 31.97 | ? | 24.84 | 25.18 | 0.6827 | 0.7201 |
| SR3+ (400M, DF2K + OST) | 27.34 | ? | 23.84 | 24.36 | 0.662 | 0.719 |
| SR3+ (400M, 61M Dataset) | 24.32 | 32.37 | 24.89 | 25.74 | 0.6922 | 0.7547 |
- SR3+ 具有 40M 参数,在 RealSR 和 DRealSR 上实现了与 Real-ESRGAN 相当的 FID(10k)。
- 更大规模的 SR3+ 模型(400M)在相同数据上训练,获得更好的 FID,在 RealSR 上超越 Real-ESRGAN,在 DRealSR 上缩小差距。
- 在训练中使用高阶退化以及噪声条件增强显著提升 FID(消除任一组件时,FID 降幅超过 10 点)。
- 使用更大规模的 61M 图像数据集,在 400M 参数下 FID 提升至 32.37,纹理更加真实和连贯。
- 测试时的噪声条件增强(t_eval ≈ 0.1)提升纹理质量并保持合理的对齐,较高的 t_eval 增加错位和幻觉的风险。
- SR3+ 通常比 Real-ESRGAN 产生更锐利、更加真实的纹理,但在用 PSNR/SSIM 评估时对精确高频文本的表现可能不及 Real-ESRGAN;这些指标可能惩罚多模态输出中的合理高频细节。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。