[论文解读] Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
MTDiff 使用一个由 GPT 支撑的扩散模型,通过提示学习实现多任务离线强化学习的规划和数据合成,在 Seen 和 Unseen 任务上提升规划性能并增加数据。
Diffusion models have demonstrated highly-expressive generative capabilities in vision and NLP. Recent studies in reinforcement learning (RL) have shown that diffusion models are also powerful in modeling complex policies or trajectories in offline datasets. However, these works have been limited to single-task settings where a generalist agent capable of addressing multi-task predicaments is absent. In this paper, we aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution. Specifically, we propose Multi-Task Diffusion Model ( extsc{MTDiff}), a diffusion-based method that incorporates Transformer backbones and prompt learning for generative planning and data synthesis in multi-task offline settings. extsc{MTDiff} leverages vast amounts of knowledge available in multi-task data and performs implicit knowledge sharing among tasks. For generative planning, we find extsc{MTDiff} outperforms state-of-the-art algorithms across 50 tasks on Meta-World and 8 maps on Maze2D. For data synthesis, extsc{MTDiff} generates high-quality data for testing tasks given a single demonstration as a prompt, which enhances the low-quality datasets for even unseen tasks.
研究动机与目标
- 学习一个能处理多样化多任务离线 RL 数据的单一模型的动机。
- 研究扩散模型如何建模多模态的多任务轨迹。
- 开发面向提示、基于变换器的扩散方法用于规划(MTDiff-p)和数据合成(MTDiff-s)。
- 展示 MTDiff 能泛化到未见任务并提高数据效率。
提出的方法
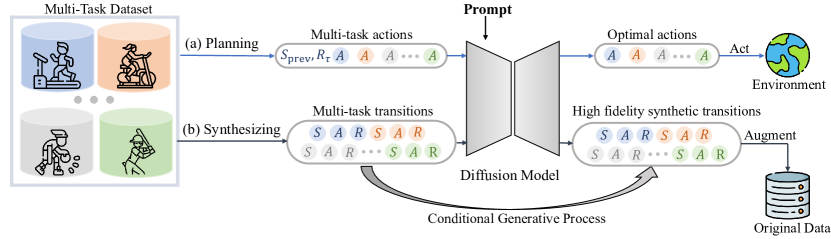
- 将多任务轨迹建模表述为使用扩散模型的条件去噪问题。
- 使用基于 GPT2 的变换器骨干来在带任务提示的条件下建模序列轨迹。
- 在规划模式(MTDiff-p)中,对提示和回报进行条件约束,通过无分类器引导生成最优动作序列。
- 在数据合成模式(MTDiff-s)中,基于任务提示合成转移(状态、动作、奖励)用于数据增强。
- 引入灵活的提示方案,其中示范作为任务条件提示而非 one-hot ID。
- 通过扩散反向过程训练以最小化去噪损失,并可选择应用低温采样以获得高似然序列。
实验结果
研究问题
- RQ1单个扩散模型是否能够在多任务离线 RL 任务之间学习并泛化?
- RQ2与基线相比,基于提示的扩散模型是否能提升多任务 RL 的规划质量?
- RQ3基于扩散的数据合成能否有效为 Seen 和 Unseen 任务扩增离线数据集?
- RQ4与单任务增强方法相比,多任务扩散对数据效率和泛化有何影响?
主要发现
| 方法 | 近似最优 | 次优 |
|---|---|---|
| CARE (Online) | 50.8±1.0 | - |
| PaCo (Online) | 57.3±1.3 | - |
| MTDT | 20.99±2.66 | 20.63±2.21 |
| PromptDT | 45.68±1.84 | 39.76±2.79 |
| MTBC | 60.39±0.86 | 34.53±1.25 |
| MTCQL | - | - |
| MTIQL | 56.21±1.39 | 43.28±0.90 |
| MTDiff-p (ours) | 59.53±1.12 | 48.67±1.32 |
| MTDiff-p-onehot (ours) | 61.32±0.89 | 48.94±0.95 |
- MTDiff-p 在多任务规划上超越 Meta-World MT50-rand 和 Maze2D 的现有基线,达到更高的平均成功率。
- MTDiff-s 能合成高保真度的多任务数据,提升多项任务的离线 RL 性能,包括未见任务。
- 带提示的 MTDiff-p 能实现对未见任务的少-shot 泛化,在适应测试中优于 one-hot 基线。
- MTDiff-s 合成的数据带来显著的策略改进,优于单任务增强方法(S4RL、RAD)在离线 RL。
- 在多任务训练中任务数量的增加会带来数据合成性能的逐步提升,表明有效的多任务知识共享。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。