[论文解读] Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Directed Diffusion 通过使用用户提供的边界框编辑交叉注意力图,在文本引导扩散中对定向对象实现粗略位置控制,无需模型训练。
Text-guided diffusion models such as DALLE-2, Imagen, eDiff-I, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are of very high quality. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. The missing capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work, we take a particularly straightforward approach to providing the needed direction. Drawing on the observation that the cross-attention maps for prompt words reflect the spatial layout of objects denoted by those words, we introduce an optimization objective that produces ``activation'' at desired positions in these cross-attention maps. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. Directed Diffusion provides easy high-level positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
研究动机与目标
- 通过在扩散生成的场景中实现对明确对象放置来激发讲故事与构成性的动机。
- 提供一种简单、无需训练的方法,在单幅或相关图像中控制多个对象的位置。
- 通过扩散过程维持放置对象与背景之间的一致性。
- 提供一个轻量级实现,能够与预训练扩散模型集成。
- 在无需定制重新训练的情况下,支持开集、零-shot 的人物与物体放置。
提出的方法
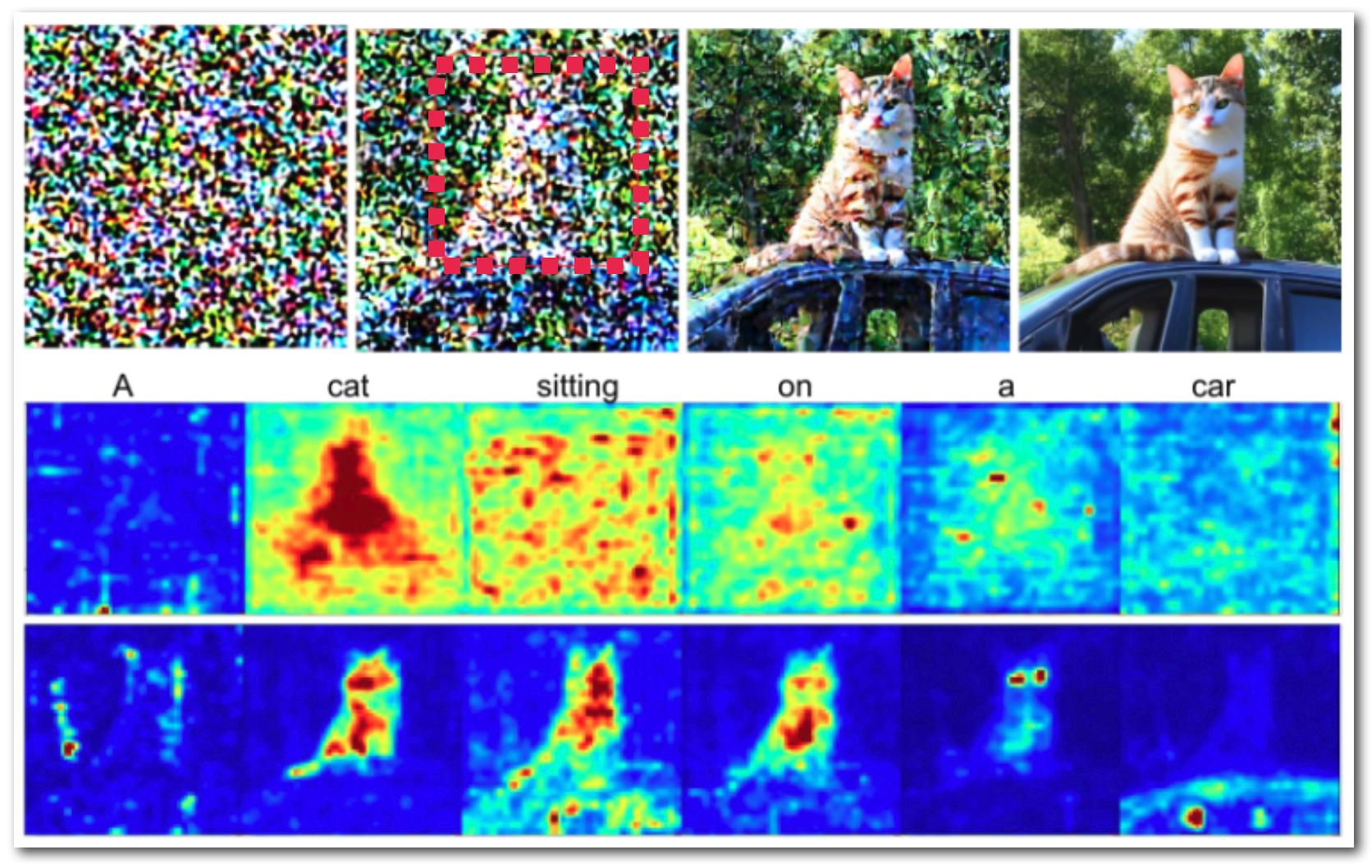
- 在预训练扩散模型中利用交叉注意力映射,将提示词与空间区域联系起来。
- 定义边界框和定向提示词,以在去噪初期引导对象定位。
- 引入一个注意力编辑阶段,在边界框内以高斯权重调制尾部的交叉注意力映射。
- 优化一个小的权重向量 a,使定向注意力映射与高斯目标映射在边界框内对齐,同时保持学习到的文本–图像关联。
- 使用两阶段管线:在初始去噪步骤中进行注意力编辑,随后进行带有分类器自由引导的常规扩散去噪。
- 在最小代码变更且不进行模型微调的前提下实现放置与交互控制。

实验结果
研究问题
- RQ1在不重新训练的情况下,粗略的基于边界框的引导是否能够引导在预训练扩散模型中放置特定对象?
- RQ2注意力引导的放置在处理多个定向对象及其与场景的交互方面表现如何?
- RQ3该方法在放置对象与背景之间是否保持上下文一致性(光照、阴影)?
- RQ4与现有的开集放置方法相比,Directed Diffusion 在易用性和质量方面如何?
主要发现
- 该方法提供了在不对预训练模型进行微调的情况下,对多个对象进行简单的高级定位控制。
- 放置的对象与背景整合连贯,并呈现诸如阴影等上下文交互。
- 该方法通过对权重向量的小幅优化,使定向交叉注意力映射在边界框内与高斯目标相对齐。
- 该管线仅需几行代码即可实现,并保留了预训练模型的文本–图像对齐性。
- 通过在场景或帧之间实现定向对象的放置及其交互,提升了构成性和讲故事能力。
- 实验结果中,以 CLIP 为基础得到的提示与合成图像之间的相似度与现有方法相比相当或更好(如论文所述)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。