[论文解读] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
DistServe 将预fill 与 decoding 分拆到不同的 GPU 上,协同优化它们的资源,并优化放置以在 TTFT 和 TPOT SLOs 下实现更高的每-GPU goodput,超越最先进系统。
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Existing LLM serving systems colocate the two phases and batch the computation of prefill and decoding across all users and requests. We find that this strategy not only leads to strong prefill-decoding interferences but also couples the resource allocation and parallelism plans for both phases. LLM applications often emphasize individual latency for each phase: time to first token (TTFT) for the prefill phase and time per output token (TPOT) of each request for the decoding phase. In the presence of stringent latency requirements, existing systems have to prioritize one latency over the other, or over-provision compute resources to meet both. DistServe assigns prefill and decoding computation to different GPUs, hence eliminating prefill-decoding interferences. Given the application's TTFT and TPOT requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase. DistServe also places the two phases according to the serving cluster's bandwidth to minimize the communication caused by disaggregation. As a result, DistServe significantly improves LLM serving performance in terms of the maximum rate that can be served within both TTFT and TPOT constraints on each GPU. Our evaluations show that on various popular LLMs, applications, and latency requirements, DistServe can serve 7.4x more requests or 12.6x tighter SLO, compared to state-of-the-art systems, while staying within latency constraints for > 90% of requests.
研究动机与目标
- 动机:在 TTFT 和 TPOT 的低延迟要求下推动优化 LLM 服务的必要性。
- 识别在同地部署的服务中,prefill- decoding 干扰与资源耦合是关键瓶颈。
- 提出将 prefill 与 decoding 分离,以实现分阶段的优化。
- 开发放置和调度算法,在真实工作负载下最大化每-GPU 的 goodput。
- 在多个模型和延迟目标上评估 DistServe 相对于现有系统的性能。
提出的方法
- 将 prefill 和 decoding 阶段分散到单独的 GPU 上以消除干扰。
- 基于 TTFT 和 TPOT 要求,对每个阶段的资源分配和并行性进行协同优化。
- 开发放置算法(高节点亲和与低节点亲和)以最大化每-GPU goodput 并通过复制满足流量。
- 引入在线调度层,采用拉取式 KV cache 传输以降低内存压力和流水线气泡。
- 利用工作负载感知仿真来估计 SLO 的达成情况并指导配置搜索。
- 提供复制策略将优化后的每阶段配置扩展到更高的流量。
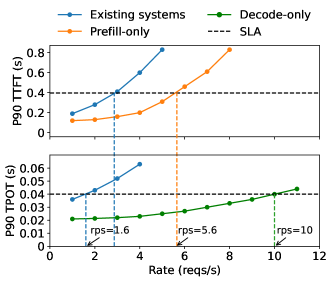
实验结果
研究问题
- RQ1在 TTFT 和 TPOT 约束下,分离 prefill 与 decoding 阶段是否能提升每-GPU 的 goodput?
- RQ2在给定集群拓扑和带宽的条件下,哪些放置与并行配置能使各阶段的 goodput 最大化?
- RQ3相较于最先进系统,DistServe 在不同的 LLM 大小、应用和延迟目标下的性能如何?
- RQ4实际挑战有哪些(例如 KV cache 传输、非均匀的提示等),在部署中如何缓解?
- RQ5是否需要在线重新规划以适应工作负载变化,这种做法有多有效?
主要发现
- DistServe 在延迟约束下能处理多达 4.48× 的请求量,超过最先进系统。
- DistServe 使 SLO 更加紧凑可达至多达 10.2×,同时在>90% 请求的延迟目标内保持。
- 分离 prefill 与 decoding 消除了 prefill–decoding 干扰,并允许阶段特定的并行性。
- 放置算法和复制在每个阶段上扩展 goodput,以高效地达到流量速率。
- KV-cache 传输通过基于拉取的机制进行管理,以降低内存压力和流水线气泡。
- 性能提升在多种 LLM、应用和延迟需求下均成立。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。