[论文解读] Efficient Adversarial Attacks on Online Multi-agent Reinforcement Learning
论文分析在线多智能体强化学习中的对抗性投毒攻击,提出混合动作与奖励攻击,在白盒、灰盒和黑盒设置下能够有效地引导智能体趋向目标策略,并在某些条件下具有可证明的保证。
Due to the broad range of applications of multi-agent reinforcement learning (MARL), understanding the effects of adversarial attacks against MARL model is essential for the safe applications of this model. Motivated by this, we investigate the impact of adversarial attacks on MARL. In the considered setup, there is an exogenous attacker who is able to modify the rewards before the agents receive them or manipulate the actions before the environment receives them. The attacker aims to guide each agent into a target policy or maximize the cumulative rewards under some specific reward function chosen by the attacker, while minimizing the amount of manipulation on feedback and action. We first show the limitations of the action poisoning only attacks and the reward poisoning only attacks. We then introduce a mixed attack strategy with both the action poisoning and the reward poisoning. We show that the mixed attack strategy can efficiently attack MARL agents even if the attacker has no prior information about the underlying environment and the agents' algorithms.
研究动机与目标
- 在安全关键应用中激励对MARL的安全性与可信度关注。
- 建模一个能够操控奖励和/或动作以引导智能体走向目标策略或更高的攻击者定义奖励的攻击者。
- 研究在白盒、灰盒、黑盒设置下的攻击有效性,并识别单模态攻击的局限性。
- 提出并分析混合攻击策略,以在各种条件下实现子线性攻击成本与损失。
提出的方法
- 对投毒攻击框架进行形式化定义,攻击者可以在每一步覆盖动作和/或奖励。
- 将攻击成本定义为动作覆盖和奖励扰动之和,并在两个目标下定义攻击损失:(i) 强制目标策略,(ii) 最大化攻击者定义的奖励。
- 引入并分析白盒、灰盒、黑盒攻击策略,包括 d-份额动作投毒、eta-间隙奖励投毒,以及混合策略。
- 提供理论保证,给出在何种条件下目标策略成为唯一的纳什均衡/协方均衡/一致性均衡,以及对攻击成本与损失的界限。
- 表明纯动作攻击或纯奖励攻击在某些多主体博弈中的局限性,从而激励高效且有效的混合策略。
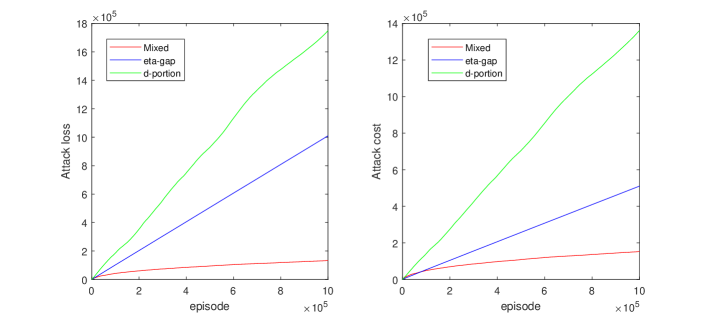
实验结果
研究问题
- RQ1攻击者是否能够在不同信息设置(白盒、灰盒、黑盒)下高效地将在线MARL智能体引导至预定义的目标策略或攻击者指定的奖励目标?
- RQ2在什么条件下仅动作投毒或仅奖励投毒的攻击会失败,混合攻击如何克服这些局限?
- RQ3不同攻击策略在总交互步数的子线性扩展方面的成本与损失权衡如何?
- RQ4混合攻击在不同MARL算法和环境中引导智能体趋向纳什均衡/协商均衡/一致性均衡的表现如何?
- RQ5在最佳事后悔论下(best-in-hindsight regret)及策略唯一性方面,能建立哪些理论保证来证明攻击有效性?
主要发现
- 单纯的动作投毒或奖励投毒在某些博弈与设定中可能无效。
- d-份额动作投毒攻击在条件1下可使目标策略成为唯一的纳什均衡/协商均衡/一致性均衡。
- eta-间隙奖励攻击在条件2下可将目标策略强制为唯一的纳什均衡/协商均衡/一致性均衡。
- 灰盒混合攻击与黑盒近似混合攻击可实现子线性损失和成本,从而驱动收敛到目标策略。
- 在子线性最佳事后悔论下,攻击损失与成本可由涉及 R_min 与回顾界限 R(T) 的公式界定。
- 在灰盒设置中,混合攻击在无需完全环境知识的情况下也能成功;在黑盒设置中,探索阶段可实现近似混合攻击。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。