[论文解读] Efficient Memory Management for Large Language Model Serving with PagedAttention
本文提出 PagedAttention 和 vLLM,显著降低 KV 缓存内存浪费,并将 LLM 服务吞吐量相比现有系统提升 2–4 倍,同时在请求与解码场景间实现更好的共享。
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$ imes$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
研究动机与目标
- 识别限制吞吐量的 LLM 服务中的内存分配挑战。
- 提出一种新型注意力算法,使 KV 缓存存储支持非连续,从而降低浪费。
- 设计一个分布式 LLM 服务引擎,实现内存管理与解码的协同优化。
- 在不同模型和解码场景下,展示相较 FasterTransformer 和 Orca 的吞吐量提升。
提出的方法
- 介绍 PagedAttention,它将 KV 缓存分成固定大小的块,并允许非连续的内存存储。
- 开发一个受操作系统虚拟内存启发的 KV 缓存管理器,将逻辑 KV 块映射到物理块并实现按需分配。
- 将 vLLM 与 PagedAttention 共同设计,以高效地支持提示阶段和自回归生成。
- 应用基于块的共享与写时复制(copy-on-write)来实现跨序列和束的内存共享。
- 在分页内存框架内描述对可变输入/输出长度及多种解码方法(贪婪、采样、束搜索)的处理。
- 解释具有集中调度器协调 GPU 工作节点的分布式架构。
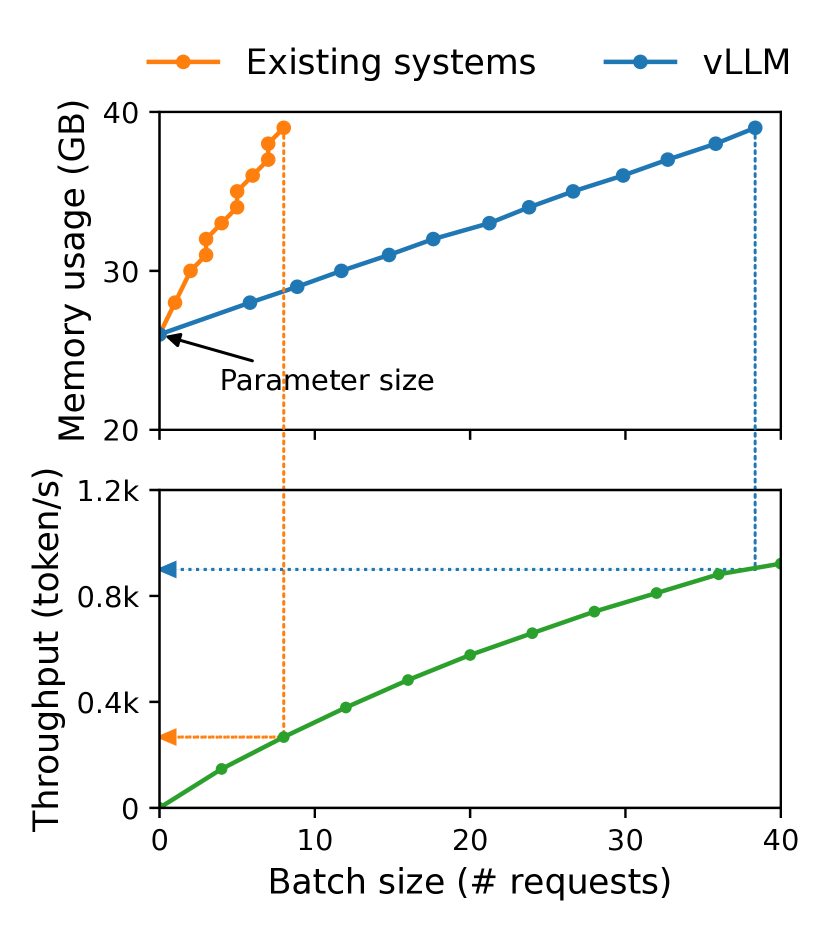
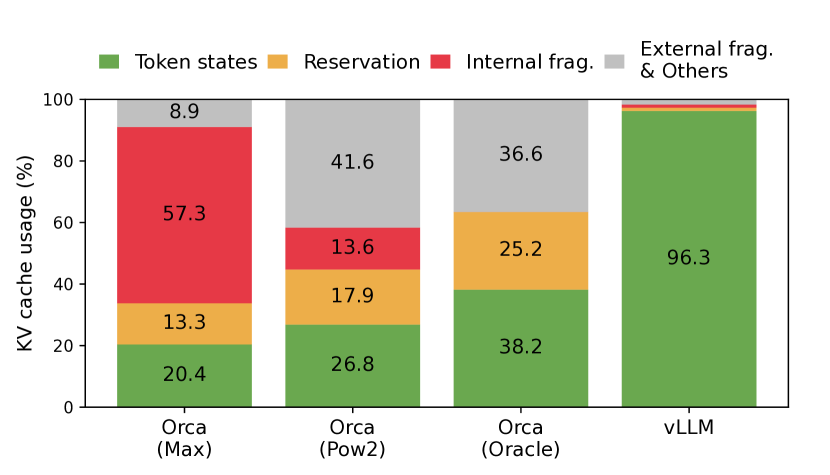
实验结果
研究问题
- RQ1非连续 KV 缓存存储如何影响 LLM 服务的内存浪费和批量吞吐量?
- RQ2分页 KV 缓存管理是否能够在保持精度的前提下,在令牌、提示、样本和束之间实现有效的内存共享?
- RQ3相比 FasterTransformer 和 Orca,vLLM 在不同模型与解码策略下能实现哪些吞吐量提升与内存节省?
- RQ4在分页内存模型中,系统如何处理可变序列长度与复杂解码(束搜索、并行采样)?
主要发现
- vLLM 在相近延迟下将 LLM 服务吞吐量提升 2-4 倍,优于现有系统。
- PagedAttention 通过允许固定大小的 KV 块和非连续存储,降低 KV 缓存内存浪费。
- 通过基于块的管理和写时复制实现跨序列和解码候选的内存共享,减少冗余的 KV 缓存拷贝。
- 支持提示和前缀的共享,为常用前缀带来可观的内存节省。
- 该方法可扩展至更长的序列、更大的模型以及更复杂的解码算法,同时保持精度。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。