[论文解读] Efficient Multimodal Learning from Data-centric Perspective
Bunny 表明一个小型多模态模型在经过精心浓缩的训练数据后,能超越更大的 MLLMs,在只有3B参数的情况下达到最先进的结果。
Multimodal Large Language Models (MLLMs) have demonstrated notable capabilities in general visual understanding and reasoning tasks. However, their deployment is hindered by substantial computational costs in both training and inference, limiting accessibility to the broader research and user communities. A straightforward solution is to leverage smaller pre-trained vision and language models, which inevitably cause significant performance drops. In this paper, we demonstrate the possibility of training a smaller but better MLLM with high-quality training data. Specifically, we introduce Bunny, a family of lightweight MLLMs with flexible vision and language backbones for efficient multimodal learning from selected training data. Experiments show that our Bunny-4B/8B outperforms the state-of-the-art large MLLMs on multiple benchmarks. We expect that this work can provide the community with a clean and flexible open-source tool for further research and development. The code, models, and data can be found in https://github.com/BAAI-DCAI/Bunny.
研究动机与目标
- 由于 MLLMs 的高训练/推理成本,需在可负担且性能高的多模态模型方面提供动机。
- 提出 Bunny,一系列具有灵活骨干网络的小型 MLLMs,并采用以数据为中心的训练策略。
- 证明数据浓缩和仔细微调可以缩小甚至超越与更大模型的差距。
提出的方法
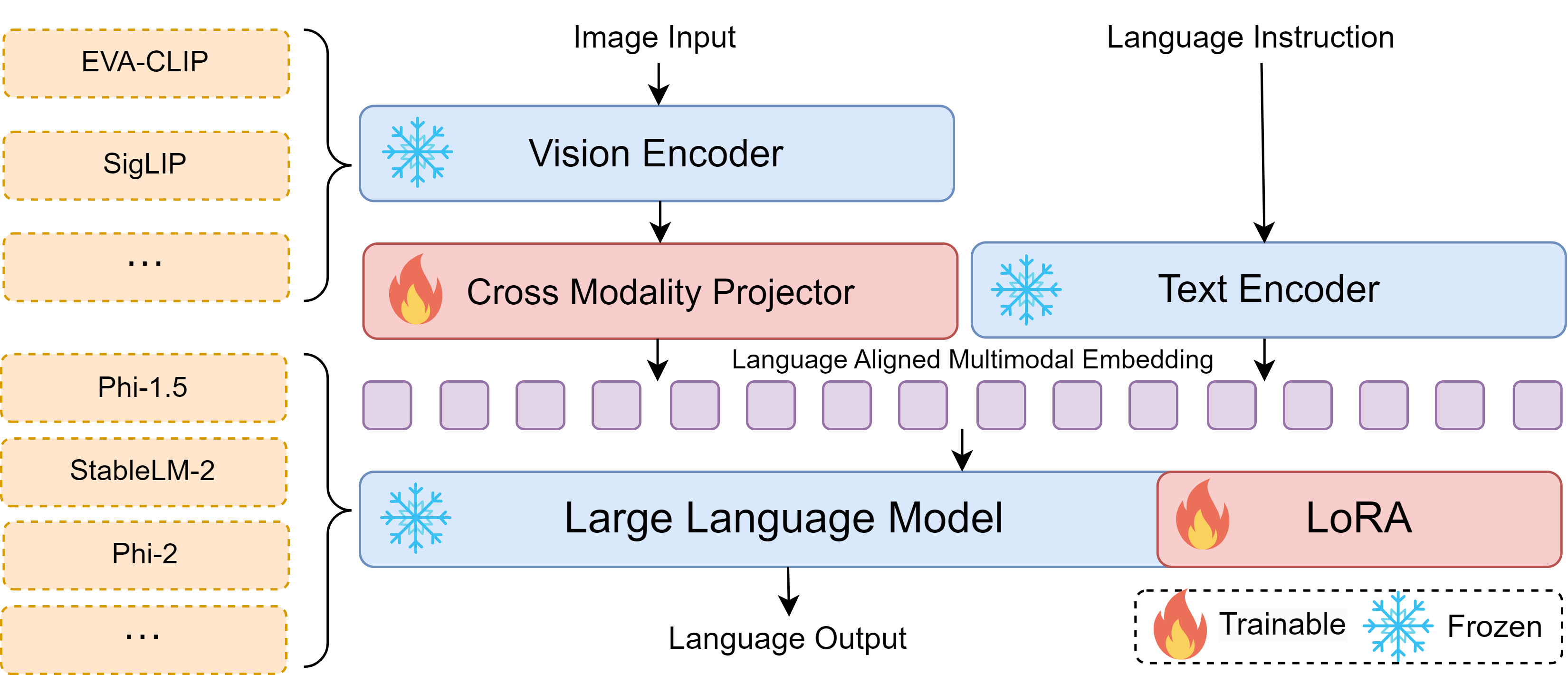
- 引入 Bunny,具备即插即用的视觉编码器和LLM骨干(SigLIP-SO, EVA-CLIP, Phi-2 等)。
- 通过将 LAION-2B 压缩成 2M 的核心集合,使用 CLIP 嵌入和基于聚类的选择来构建高质量的预训练数据。
- 创建微调数据 Bunny-695K,结合多模态数据集和高质量文本数据,以保持认知能力。
- 使用两阶段训练:(1)通过跨模态投影器对齐视觉和文本嵌入;(2)在 LLM 和投影器上使用 LoRA 进行视觉指令微调。
- 两阶段以下一字元预测的交叉熵损失训练;推荐使用 LoRA 而非全量微调。
- 在包括 MME 感知/认知、MMBench、SEED-Bench、MMMU、VQA-v2、GQA、ScienceQA-IMG 和 POPE 的 11 个基准上进行评估。
实验结果
研究问题
- RQ1一个小型、数据优化的多模态模型是否能在标准基准上超越更大的 MLLMs?
- RQ2数据浓缩和高质量微调数据对性能相对于模型大小的影响如何?
- RQ3哪些骨干组合(视觉编码器 + LLM)为 Bunny 提供最佳权衡?
主要发现
| 模型 | 视觉编码器 | LLM | MME^P | MME^C | MMB^T | MMB^D | SEED | MMMU^V | MMMU^T | VQA^v2 | GQA | SQA^I | POPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bunny | SigLIP-SO (0.4B) | Phi-2 (2.7B) | 1488.8 | 289.3 | 69.2 | 68.6 | 62.5 | 38.2 | 33.0 | 79.8 | 62.5 | 70.9 | 86.8 |
- Bunny-3B with SigLIP-SO and Phi-2 outperforms many lightweight MLLMs of similar size and even some larger models on multiple benchmarks.
- Bunny-3B achieves competitive or superior results compared to LLaVA-v1.5-13B on several tasks despite having about a quarter of the parameters.
- Among backbones, SigLIP-SO + Phi-2 gives the best overall performance across benchmarks.
- Data condensation and maintaining high-quality pure-text data in fine-tuning improve cognition and multimodal capabilities.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。