[论文解读] Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
本论文在 FLAN-T5-XL 上针对数据规模和任务,对 PEFT 方法(LoRA、IA3、BitFit、Prompt Tune)进行基准测试,并提出一个选择方法的框架;研究发现,在低/中等数据量下,完整微调通常收敛更快,而在数据量较大时,PEFT 表现出色,且在参数效率方面具有潜力。
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
研究动机与目标
- 在数据规模和任务类型(分类和生成)上,为具有代表性的 LLM(FLAN-T5)提供统一、全面的 PEFT 技术基准测试。
- 分析收敛速度、准确性和其他指标,以了解在何时使用 PEFT 与完整微调。
- 识别在不同 PEFT 方法中,模型的哪些部分(层/子模块)在训练时影响最大。
- 提出一个基于任务类型和数据可用性的实用框架,用于选择 PEFT 方法。
- 展示潜在的消融研究,以在保持或提升性能的同时减少训练参数。
提出的方法
- 在 FLAN-T5-XL 上,对比四种 PEFT 技术(LoRA、(IA)3、prompt tuning、BitFit)与完整微调,覆盖多个数据集和数据规模。
- 对于 AG News 与 CoLA,使用精确字符串匹配准确度;对于 E2E NLG 与 SAMSum,使用 ROUGE-L。
- 进行消融研究,改变训练的层/子模块以及被修改的组件(如注意力层与密集块等)。
- 分析收敛速度、内存使用和计算成本,以推导效率-准确性的权衡。
- 提供参数数量数据,并通过按参数(以及按运行时间)归一化来比较效率。
- 在资源约束和数据可用性条件下,建立何时偏好全量微调或 PEFT 的经验性指南。
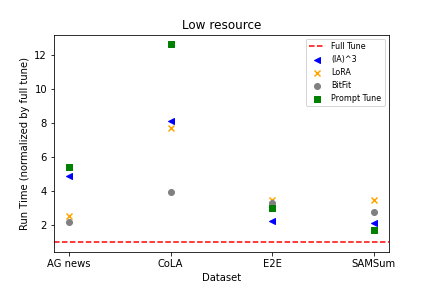
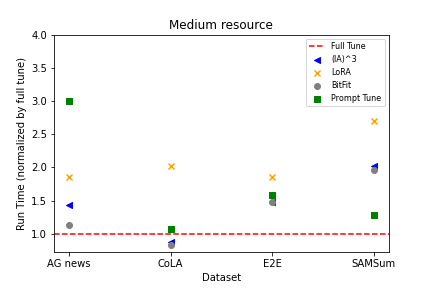
实验结果
研究问题
- RQ1在低/中/高数据规模下,不同 PEFT 技术在 FLAN-T5-XL 的分类和生成任务中的表现如何?
- RQ2在不同数据区间中,PEFT 相对于全微调的收敛特性和资源成本是什么?
- RQ3在应用 PEFT 方法时,哪些模型组件(层、注意力模块、激活函数)最为关键?
- RQ4通过对特定层或子模块进行有选择性的训练,PEFT 方法是否可以在不损害性能的情况下进一步优化?
- RQ5有哪些框架可以在给定任务和数据区间内指导从业者选择合适的 PEFT 技术?
主要发现
- 在低/中资源数据下,PEFT 技术在收敛速度方面通常落后于全量微调,但在较高数据量下可以达到甚至超过性能。
- BitFit 和 LoRA 在低/中资源场景下通常表现良好,而更多数据时全量微调的相对性能提升。
- $(IA)^{3}$ 通过逐元素缩放提供内存效率,在消融研究中可显著减少参数数量,同时对性能损失很小。
- 注意力级别修改和后备层的选择对于下游性能尤为重要,后层或随机层的选择在 $(IA)^{3}$ 中通常优于早层选择。
- 在不 sacrifices 性能的前提下,可以实现显著的参数减少(通常约一半或更多),从而实现更高效的适配。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。