[论文解读] Executable Code Actions Elicit Better LLM Agents
CodeAct 使 LLM 代理能够输出可执行的 Python 代码作为动作,集成 Python 解释器以执行、修订和组合工具调用,从而在性能上优于文本/JSON 动作格式,并使基于开源的 CodeActAgent 能从 Llama2 和 Mistral 微调出 CodeActInstruct。
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools). This work proposes to use executable Python code to consolidate LLM agents' actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations through multi-turn interactions. Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark shows that CodeAct outperforms widely used alternatives (up to 20% higher success rate). The encouraging performance of CodeAct motivates us to build an open-source LLM agent that interacts with environments by executing interpretable code and collaborates with users using natural language. To this end, we collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. We show that it can be used with existing data to improve models in agent-oriented tasks without compromising their general capability. CodeActAgent, finetuned from Llama2 and Mistral, is integrated with Python interpreter and uniquely tailored to perform sophisticated tasks (e.g., model training) using existing libraries and autonomously self-debug.
研究动机与目标
- 推动扩展 LLM 代理的动作空间,超越文本/JSON,以应对真实世界的任务。
- 提出一个统一的动作空间,使用可执行的 Python 代码(CodeAct)并与 Python 解释器集成。
- 展示 CodeAct 在控制和数据流、可重用性以及基于错误的自动自我调试方面的优势。
- 在跨 17 个模型的多语言评估中展示优势,并引入 CodeActInstruct 进行指令微调。
提出的方法
- 将 CodeAct 定义为输出由嵌入式 Python 解释器执行的 Python 代码动作。
- 使用 API-Bank 和一个新的 M3 ToolEval 基准,将 CodeAct 与文本/JSON 动作在原子工具使用和复杂多工具任务上的表现进行比较。
- 通过 82 个多轮、多工具任务来评估工具组合性能的 M3 ToolEval。
- 创建包含 7k 条多轮轨迹的 CodeActInstruct,用于训练 CodeActAgent 并研究交互中的自我提升。
- 在 CodeActInstruct 及通用对话的基础上,对 CodeActAgent(以 LLaMA-2 和 Mistral-7B 为骨干网络)进行微调,以评估在代理任务和通用基准上的表现。
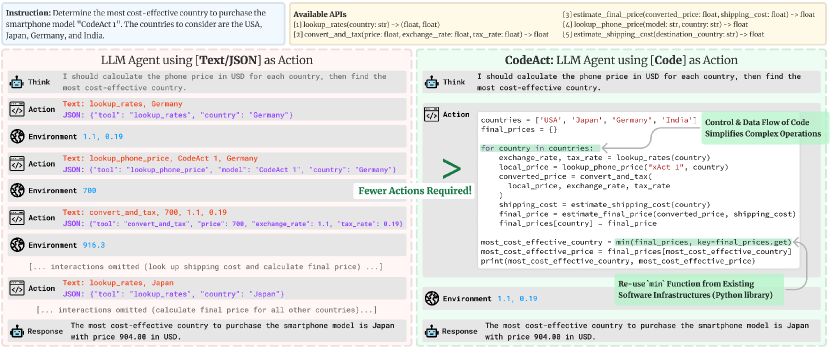
实验结果
研究问题
- RQ1LLM 对代码数据的熟悉度是否为 CodeAct 在原子工具使用中的表现胜过文本/JSON 提供优势(RQ1)?
- RQ2Python 的控制流和数据流是否在复杂的多工具任务中提升性能(RQ2)?
- RQ3多轮交互和现有软件如何影响 CodeAct 的鲁棒性和能力(RQ3)?
- RQ4CodeAct 是否可用于训练能够进行自我调试的开源 LLM 代理,以执行复杂任务(RQ4)?
主要发现
- CodeAct 在原子工具调用正确性方面达到与文本/JSON 相当或更好的水平,开源模型的提升更大。
- 在需要多工具的复杂任务上,CodeAct 在 M3 ToolEval 基准测试中实现最高 20% 的绝对提升,且使用的动作数量最多减少 30%。
- CodeActInstruct(7k 条轨迹)提升代理性能,将 CodeActInstruct 与通用对话混合使用可保留广泛能力。
- CodeActAgent(在 CodeActInstruct 上微调)在 MINT 和 M3 ToolEval 的领域内外代理任务上均优于开源 LLM,并且能够推广到文本动作格式。
- CodeActAgent 可通过利用 Python 错误信息、库的导入以及诸如 Pandas、Scikit-Learn 和 Matplotlib 等外部工具实现自动自我调试。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。