[论文解读] Explainable Automated Debugging via Large Language Model-driven Scientific Debugging
AutoSD 使用大型语言模型(LLMs)通过调试器界面模拟科学调试,生成假设与解释以实现自动调试,同时保持具有竞争力的修复性能。一次人工研究表明,解释有助于开发者的决策。
Automated debugging techniques have the potential to reduce developer effort in debugging, and have matured enough to be adopted by industry. However, one critical issue with existing techniques is that, while developers want rationales for the provided automatic debugging results, existing techniques are ill-suited to provide them, as their deduction process differs significantly from that of human developers. Inspired by the way developers interact with code when debugging, we propose Automated Scientific Debugging (AutoSD), a technique that given buggy code and a bug-revealing test, prompts large language models to automatically generate hypotheses, uses debuggers to actively interact with buggy code, and thus automatically reach conclusions prior to patch generation. By aligning the reasoning of automated debugging more closely with that of human developers, we aim to produce intelligible explanations of how a specific patch has been generated, with the hope that the explanation will lead to more efficient and accurate developer decisions. Our empirical analysis on three program repair benchmarks shows that AutoSD performs competitively with other program repair baselines, and that it can indicate when it is confident in its results. Furthermore, we perform a human study with 20 participants, including six professional developers, to evaluate the utility of explanations from AutoSD. Participants with access to explanations could judge patch correctness in roughly the same time as those without, but their accuracy improved for five out of six real-world bugs studied: 70% of participants answered that they wanted explanations when using repair tools, while 55% answered that they were satisfied with the Scientific Debugging presentation.
研究动机与目标
- 激励可解释的自动化调试,使自动推理与人类调试过程保持一致。
- 提出 AutoSD:利用 LLM 通过调试器界面生成假设和调试实验。
- 展示 AutoSD 在保持可追溯解释的同时实现具有竞争力的程序修复性能。
- 通过面向开发者的人类研究评估解释的效用。
提出的方法
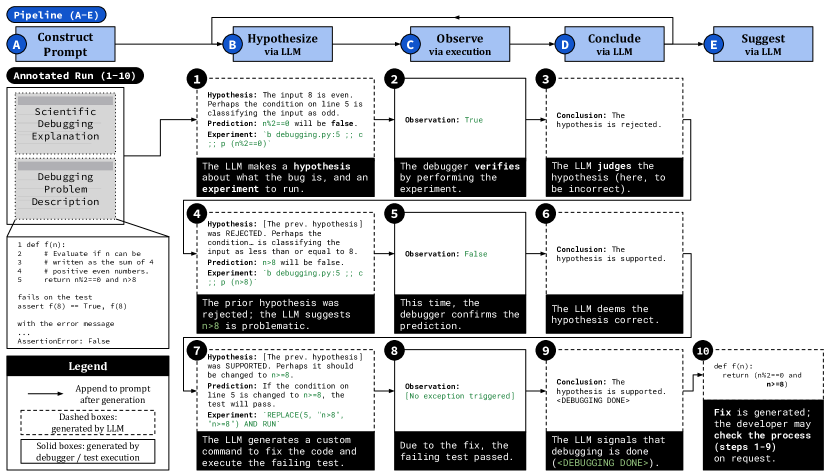
- 以详细的科学调试框架提示 LLM 以生成假设及相应的调试实验。
- 执行所提出的调试器命令或编辑并执行脚本以验证假设。
- 使用调试器结果通过“假设-观察-推断”迭代来细化假设,直到收到 <DONE> 信号或达到迭代上限。
- 生成修补并给出追踪中间推理步骤的解释,供开发者审阅。
实验结果
研究问题
- RQ1RQ1 可行性:在提供解释的同时,AutoSD 是否与现有 APR 技术具有竞争力?
- RQ2RQ2 调试器消融:<DONE> 标记是否与更高准确性相关,预测的调试器输出如何影响性能?
- RQ3RQ3 不同 LLM 下的表现变化:在不同底层 LLM 下 AutoSD 的性能如何变化?
- RQ4RQ4 开发者收益:解释是否有助于开发者在现实情境中判断补丁正确性?
- RQ5RQ5 开发者接受度:解释对开发者来说是否可接受且令人期望?
主要发现
| Benchmark | Plausible (Template-based) | Plausible (LLM-Base) | Plausible (AutoSD) | Correct (LLM-Base) | Correct (AutoSD) |
|---|---|---|---|---|---|
| ARHE | 85.77 ± 4.20 | 179 | 189 | 177 | 187 |
| Defects4J v1.2 | 24 | 41 | 87 | 76 | |
| Defects4J v2.0 | 11 | 28 | 110 | 113 |
- AutoSD 在三个基准上(ARHE、Defects4J v1.2/v2.0)实现了与基线相比具有竞争力的修复性能,同时也提供了解释。
- <DONE> 标记表示更高的精确性,指示 AutoSD 何时更可能产生正确的补丁,带有调试器背书的结果提升了可靠性。
- 使用更大或更强的 LLM 往往提升 AutoSD 的性能,在实验中以 ChatGPT 作为一个强有力的默认选项。
- 在一项人类研究中,解释在6个真实世界错误中的5个提高了开发者的准确性,参与者也认为对 APR 工具有价值。
- 70% 的参与者希望在 APR 工具中提供解释,55% 对科学调试呈现表示满意。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。