[论文解读] FICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion
FICE 编辑利用文本描述来引导时尚图片的 GAN 反演,在保留姿态/身份的同时,通过基于 CLIP 的语义和图像拼接整合新服装。
Fashion-image editing represents a challenging computer vision task, where the goal is to incorporate selected apparel into a given input image. Most existing techniques, known as Virtual Try-On methods, deal with this task by first selecting an example image of the desired apparel and then transferring the clothing onto the target person. Conversely, in this paper, we consider editing fashion images with text descriptions. Such an approach has several advantages over example-based virtual try-on techniques, e.g.: (i) it does not require an image of the target fashion item, and (ii) it allows the expression of a wide variety of visual concepts through the use of natural language. Existing image-editing methods that work with language inputs are heavily constrained by their requirement for training sets with rich attribute annotations or they are only able to handle simple text descriptions. We address these constraints by proposing a novel text-conditioned editing model, called FICE (Fashion Image CLIP Editing), capable of handling a wide variety of diverse text descriptions to guide the editing procedure. Specifically with FICE, we augment the common GAN inversion process by including semantic, pose-related, and image-level constraints when generating images. We leverage the capabilities of the CLIP model to enforce the semantics, due to its impressive image-text association capabilities. We furthermore propose a latent-code regularization technique that provides the means to better control the fidelity of the synthesized images. We validate FICE through rigorous experiments on a combination of VITON images and Fashion-Gen text descriptions and in comparison with several state-of-the-art text-conditioned image editing approaches. Experimental results demonstrate FICE generates highly realistic fashion images and leads to stronger editing performance than existing competing approaches.
研究动机与目标
- 在不需要目标服装图像的情况下,用自然语言描述来激励和实现对时尚图像的编辑。
- 在仅编辑服装区域的同时,保持主体姿态、身份和背景不变。
- 利用 CLIP 与辅助可微模型在反演过程中强化语义、姿态和图像一致性约束。
- 引入潜在码正则化以提升真实感并将编辑约束在一个定义明确的潜在空间内。
提出的方法
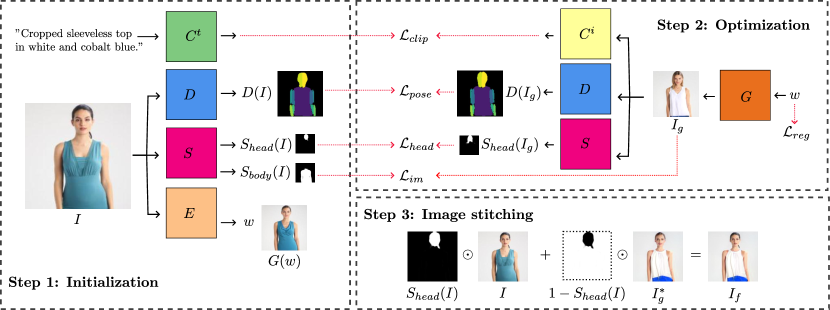
- 使用三阶段流程:初始化、受限的 GAN 反演,以及图像拼接。
- 以预训练的 StyleGAN2 生成器作为编辑骨干。
- 使用基于 CLIP 的语义损失将编辑后的图像与文本描述对齐。
- 结合 DensePose 实现姿态保持,以及用于区域感知编辑的分割模型。
- 在 W+ 空间对扩展潜在码进行正则化,以减少不同空间之间的分布漂移。
- 用原始图像拼接编辑区域,以保持身份并最小化伪影。

实验结果
研究问题
- RQ1仅靠文本描述能否在保持姿态与身份的同时引导现实的时尚图像编辑?
- RQ2基于 CLIP 的语义、姿态约束和区域感知损失是否能比通用 GAN 编辑产生更优的文本驱动编辑?
- RQ3潜在码正则化是否提升了基于 StyleGAN 的时尚编辑的真实感与一致性?
- RQ4将文本描述与 VITON 和 Fashion-Gen 数据集中的真实世界时尚图像结合时,FICE 的表现如何?
主要发现
- FICE 生成的时尚编辑具有高度真实感,能保持姿态和身份。
- 在定性和定量评估中,FICE 的表现优于其他基于文本的编辑方法。
- CLIP 语义、姿态保持和图像区域损失的组合带来令人信服的服装整合。
- 潜在码正则化通过将扩展的 W+ 码与原始潜在空间对齐,帮助维持图像真实感。
- 图像拼接进一步提高保真度并减少区域边界的伪影。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。