[论文解读] Fine-grained Hallucination Detection and Editing for Language Models
本文提出对 LM 幻觉的细粒度分类法,提出 Fava 用于检测与编辑,并引入 FavaBench——一个包含约 1,000 个人评估的基准,覆盖多种语言模型,结果显示 Fava 在检测和纠正事实错误方面优于基线。
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
研究动机与目标
- 为信息获取任务中的语言模型输出开发一个细粒度的幻觉分类法。
- 创建一个基准(FavaBench),在多个模型和领域中对 LM 幻觉进行跨段落层级注释。
- 构建一个带检索增强的编辑模型(Fava),用于检测并纠正 LM 输出中的事实错误。
- 证明细粒度的检测与编辑在事实性方面优于强基线。
提出的方法
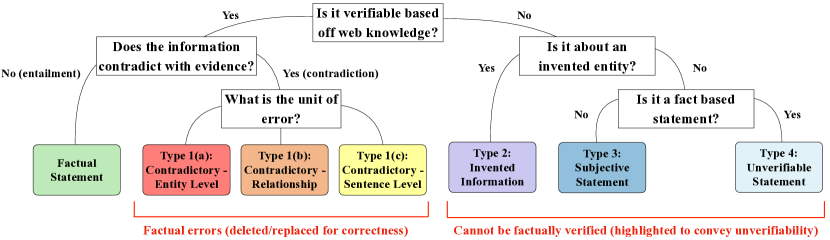
- 提出六类型的细粒度幻觉分类法,以及两项任务评估:检测(跨段落级别的错误类型识别)和编辑(跨段落级别的更正)。
- 构建 FavaBench,对约 1,000 个模型输出在跨段落层面进行标注,覆盖多样化提示和领域。
- 训练 Fava 作为带检索增强的编辑模型,利用检索到的文档来识别并标记LM输出中的事实错误。
- 通过三步管线生成高质量的合成训练数据:种子段落生成、使用分类法有针对性地插入错误、以及后处理。
- 在合成数据上初始化并训练一个编辑型语言模型(Fava),使用检索模块选择相关文档(前五条)作为上下文。
- 在细粒度检测(按错误类型的 F1)和编辑(基于 FActScore 的提升)方面,对比评估 Fava 与 ChatGPT、GPT-4 以及带检索增强的基线。

实验结果
研究问题
- RQ1在信息获取任务中,LM输出的细粒度幻觉有哪些明确的类别?
- RQ2带检索增强的编辑模型是否能比强基线更有效地检测和纠正跨段落层面的事实错误?
- RQ3合成数据生成管线是否足以训练出一个能力强的细粒度幻觉检测/编辑模型?
- RQ4检索质量和上下文对事实正确性的编辑性能有何影响?
- RQ5在不同模型和领域中,幻觉类型的发生率和分布状况如何?
主要发现
- 在信息获取提示中,所有评估的模型在大多数输出中都存在幻觉。
- 实体错误最为频繁,但捏造和无法验证的错误也很常见,凸显需要细粒度检测。
- Fava 在细粒度幻觉检测和编辑有效性方面优于 ChatGPT、GPT-4 及带检索增强的基线,在 FActScore 上获得显著提升。
- 使用前5条文档的检索增强编辑相较于单文档或无检索在事实性方面有所提升。
- 更大的合成训练数据提升检测性能;更好的检索排序和基于实体的提示进一步提升编辑效果。
- 人工评估证实 Fava 的检测和编辑能力相对于强基线带来有意义的事实性改进。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。