[论文解读] Frozen Transformers in Language Models Are Effective Visual Encoder Layers
论文表明,来自经预训练的大语言模型的冻结 Transformer 块可以作为有效的视觉编码器层,覆盖广泛的 2D/3D 与视觉-语言任务,而无需语言提示或多模态预训练。
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
研究动机与目标
- 证明冻结的 LLM Transformer 块可以作为通用视觉编码器,适用于纯视觉任务。
- 表明该方法在不依赖语言输入的情况下,在多样化的任务和模态上提升性能。
- 提出一个解释,说明为什么预训练的 LLM 通过信息筛选机制增强视觉编码。
提出的方法
- 在视觉编码器与解码器之间插入一个冻结的 LLM Transformer 块,在前后加入可训练的线性层以对齐维度。
- 在训练过程中保持 LLM 块冻结,同时训练所有其他模块。
- 在包括 2D/3D 分类、动作识别、运动预测以及视觉-语言任务等多样化任务上进行评估。
- 比较使用不同的 LLM(例如 LLaMA、OPT)和不同的 Transformer 块的结果,以展示通用性。
- 提出信息筛选假说,以通过突出有信息的视觉标记来解释视觉编码的改进。
- 提供在图像、点云、视频、运动预测和 VL 基准上的实现与实验。
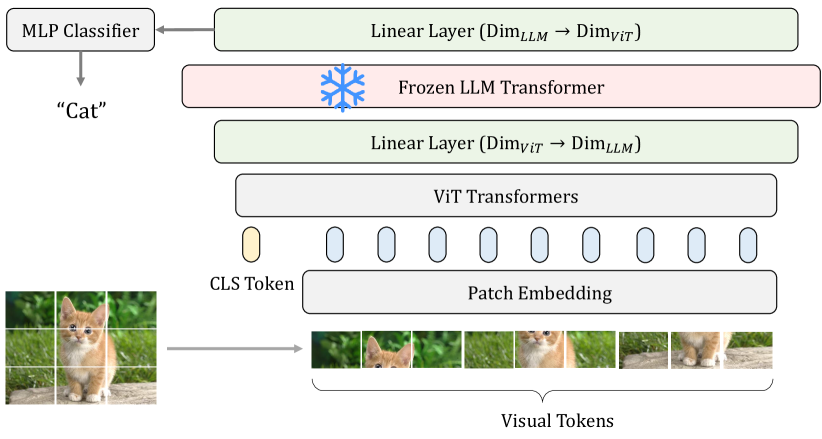
实验结果
研究问题
- RQ1冻结的来自预训练 LLM 的 Transformer 块是否可以在没有语言提示的情况下作为有效的视觉编码器?
- RQ2冻结的 LLM transformer 是否在广泛的视觉和视觉-语言任务中提升性能?
- RQ3解释 LLM transformer 为什么有助于视觉编码的机制是什么(如对有信息标记的信息筛选)?
主要发现
- 在视觉编码器之上加入冻结的 LLM transformer 块,能够在图像分类基准上持续提升准确性和鲁棒性。
- 这一改进在 2D/3D 识别任务、视频动作识别、运动预测以及 2D/3D 视觉-语言任务中都可观察到。
- 该效益在不同的 LLM(如 LLaMA、OPT)和不同的 transformer 块之间具有普遍性。
- 对 LLM transformer 进行微调可能会降低性能,表明冻结通常更有效且更简单。
- 信息筛选假说解释说,冻结的 LLM transformer 有助于集中有信息的视觉标记,从而提升它们的下游影响。
- 更大规模的 LLM 和选择合适的 transformer 层对于实现改进很重要。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。